目次
1.ubuntuをmacにインストールする
2. ubuntuを起動、SDカードの確認
3.パーティションの作成
4.GUIでパーテイションの内訳を確認してみる
追記.Ffrom CUI
1.ubuntuをmacにインストールする
1.USBカードを差し込む。$ diskutil list $ diskutil unMountDisk /dev/disk2 (USB= /dev/disk2) $ sudo dd if=ubuntu-18.4.2.iso of=/dev/disk2 bs=1m
終わったら、「無視」をクリック。
2.macをoption押しながら起動してUSBの選択肢を選択する。
3.あとは[ubuntu〜 install]をクリックしてwifi設定も含めてubuntuをinstall
ほとんどvirtualBoxと同じ方法でinstall。
2. ubuntuを起動、SDカードの確認
macの「diskutil list」と同じコマンドを打って、SDカードの内訳確認
$ dmesg | tail >>>> ... [ 6854.215650] sd 7:0:0:0: [sdc] Mode Sense: 0b 00 00 08 [ 6854.215653] sd 7:0:0:0: [sdc] Assuming drive cache: write through [ 6854.215659] sdc: sdc1
この例では/dev/sdcとして認識されてる。
3.パーティションの作成
fdiskコマンドの確認$ sudo fdisk /dev/sdc fdisk (util-linux 2.31.1) へようこそ。 ここで設定した内容は、書き込みコマンドを実行するまでメモリのみに保持されます。 書き込みコマンドを使用する際は、注意して実行してください。
・pコマンドで確認
コマンド (m でヘルプ): p ディスク /dev/sdc: 14.9 GiB, 16022241280 バイト, 31293440 セクタ 単位: セクタ (1 * 512 = 512 バイト) セクタサイズ (論理 / 物理): 512 バイト / 512 バイト I/O サイズ (最小 / 推奨): 512 バイト / 512 バイト ディスクラベルのタイプ: dos ディスク識別子: 0xf20f0c70 デバイス 起動 開始位置 最後から セクタ サイズ Id タイプ /dev/sdc1 2048 2936831 2934784 1.4G c W95 FAT32 (LBA) /dev/sdc2 2936832 14680063 11743232 5.6G 83 Linux
・dコマンドでパーティション削除
コマンド (m でヘルプ): d パーティション番号 (1,2, 既定値 2): 2 パーティション 2 を削除しました。 コマンド (m でヘルプ): d パーティション 1 を選択 パーティション 1 を削除しました。
・pで確認
コマンド (m でヘルプ): p ディスク /dev/sdc: 14.9 GiB, 16022241280 バイト, 31293440 セクタ 単位: セクタ (1 * 512 = 512 バイト) セクタサイズ (論理 / 物理): 512 バイト / 512 バイト I/O サイズ (最小 / 推奨): 512 バイト / 512 バイト ディスクラベルのタイプ: dos ディスク識別子: 0xf20f0c70
・nで新規作成(n => p => 1 => 2048)
コマンド (m でヘルプ): n パーティションタイプ p 基本パーティション (0 プライマリ, 0 拡張, 4 空き) e 拡張領域 (論理パーティションが入ります) 選択 (既定値 p): p パーティション番号 (1-4, 既定値 1): 1 最初のセクタ (2048-31293439, 既定値 2048): 2048 最終セクタ, +セクタ番号 または +サイズ{K,M,G,T,P} (2048-31293439, 既定値 31293439): 2936831 新しいパーティション 1 をタイプ Linux、サイズ 1.4 GiB で作成しました。 パーティション #1 には vfat 署名が書き込まれています。 署名を削除しますか? [Y]es/[N]o: Yes 署名は write (書き込み)コマンドを実行すると消えてしまいます。
・aで起動フラグを有効にする
コマンド (m でヘルプ): a パーティション 1 を選択 パーティション 1 の起動フラグを有効にしました。
・pで確認
コマンド (m でヘルプ): p ディスク /dev/sdc: 14.9 GiB, 16022241280 バイト, 31293440 セクタ 単位: セクタ (1 * 512 = 512 バイト) セクタサイズ (論理 / 物理): 512 バイト / 512 バイト I/O サイズ (最小 / 推奨): 512 バイト / 512 バイト ディスクラベルのタイプ: dos ディスク識別子: 0xf20f0c70 デバイス 起動 開始位置 最後から セクタ サイズ Id タイプ /dev/sdc1 * 2048 2936831 2934784 1.4G 83 Linux パーティション 1 にあるファイルシステム/RAIDの署名が完全に消去されます。
・nで2個めのパーティション作成(n => p => 2 => 2936832 => 31293439)
コマンド (m でヘルプ): n パーティションタイプ p 基本パーティション (1 プライマリ, 0 拡張, 3 空き) e 拡張領域 (論理パーティションが入ります) 選択 (既定値 p): p パーティション番号 (2-4, 既定値 2): 2 最初のセクタ (2936832-31293439, 既定値 2936832): 2936832 最終セクタ, +セクタ番号 または +サイズ{K,M,G,T,P} (2936832-31293439, 既定値 31293439): 31293439 新しいパーティション 2 をタイプ Linux、サイズ 13.5 GiB で作成しました。 パーティション #2 には ext4 署名が書き込まれています。 署名を削除しますか? [Y]es/[N]o: Yes 署名は write (書き込み)コマンドを実行すると消えてしまいます。
・pで最終確認 & 終了
コマンド (m でヘルプ): p ディスク /dev/sdc: 14.9 GiB, 16022241280 バイト, 31293440 セクタ 単位: セクタ (1 * 512 = 512 バイト) セクタサイズ (論理 / 物理): 512 バイト / 512 バイト I/O サイズ (最小 / 推奨): 512 バイト / 512 バイト ディスクラベルのタイプ: dos ディスク識別子: 0xf20f0c70 デバイス 起動 開始位置 最後から セクタ サイズ Id タイプ /dev/sdc1 * 2048 2936831 2934784 1.4G 83 Linux /dev/sdc2 2936832 31293439 28356608 13.5G 83 Linux パーティション 1 にあるファイルシステム/RAIDの署名が完全に消去されます。 パーティション 2 にあるファイルシステム/RAIDの署名が完全に消去されます。 コマンド (m でヘルプ): ^C 終了してよろしいですか? y
4.GUIでパーティションの内訳を確認してみる
deskopから、「desk」を選択。SDカードを差し込むと「boot」と「root」の両方があるのが見える。
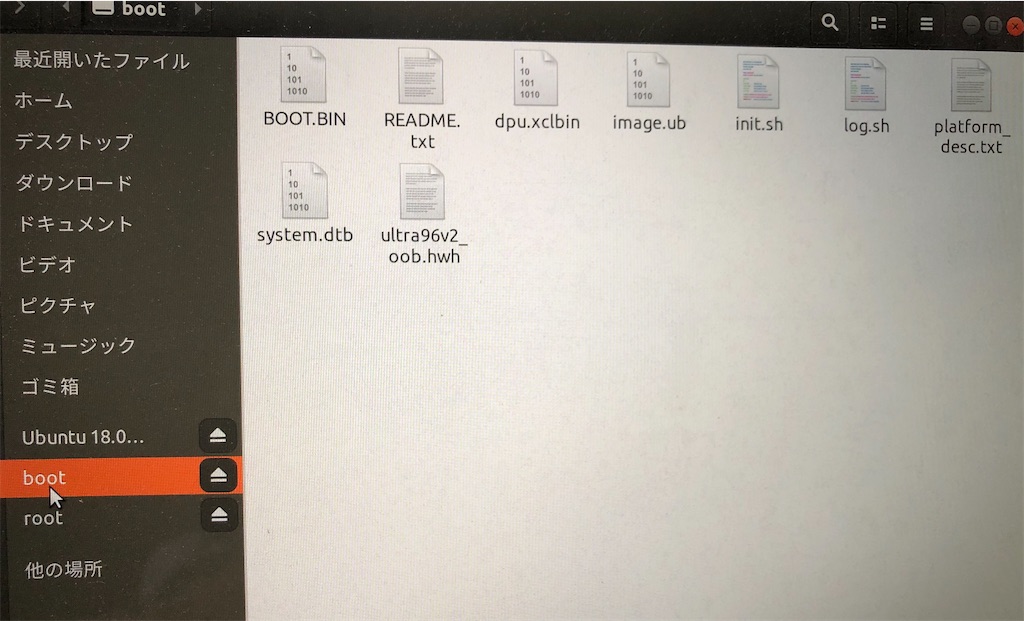


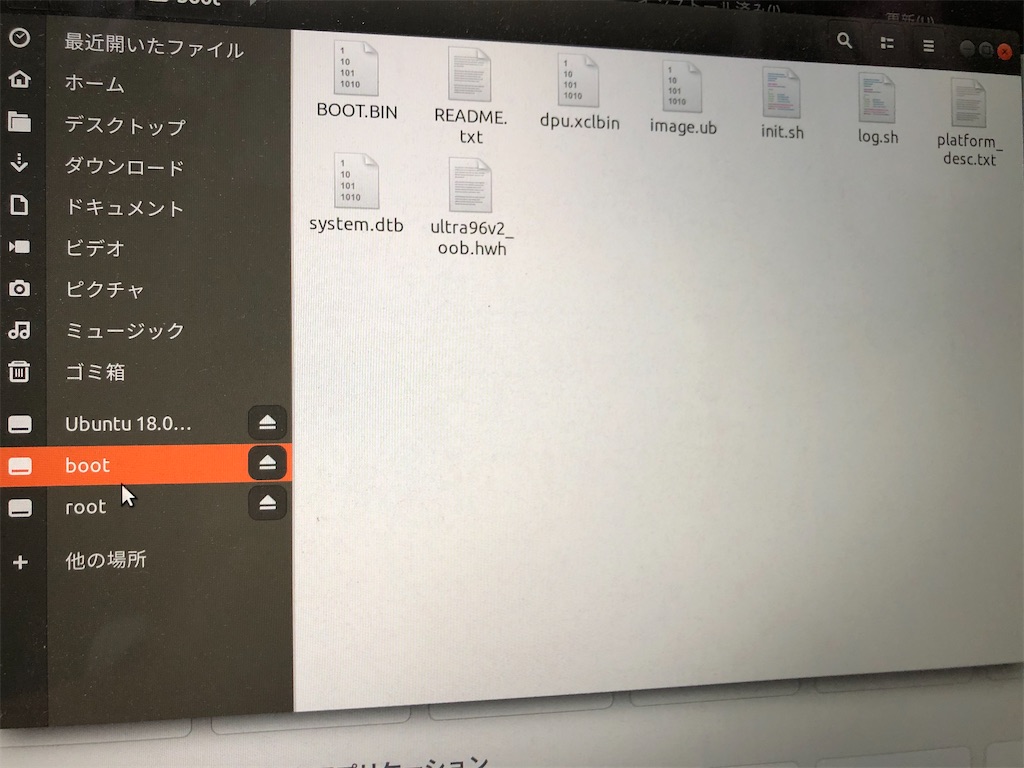
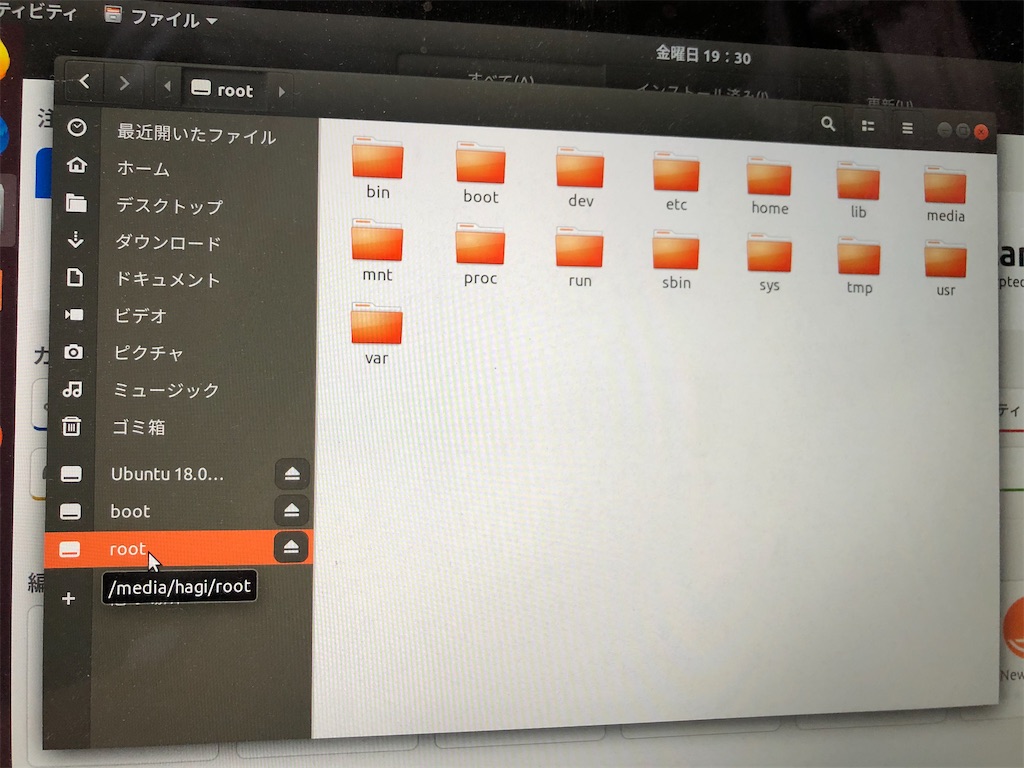
ちなみにmacでは無理で、ubuntuをOSで入れないとできない
追記.From CUI
1.HDDを仮想環境に追加
設定=>ストレージ=>「コントロール:SOTA」の右のプラスボタンをクリックで作成。
・VDI(Virtual Disk Image)
・可変サイズ
・とりあえず50GB
で作成。

50GBのHDDが追加されたか確認。
$ dmesg | grep sdb >>> [ 3.462702] sd 3:0:0:0: [sdb] 104857600 512-byte logical blocks: (53.7 GB/50.0 GiB)
2イメージの書き込み
fdiskじゃなくてpartedコマンドで作る
このサイトからinstallしたイメージをEtcherでSD CARDにコピーすれば、rootとbootは勝手に作られてる。
だからfdiskコマンドでパーティションを作ってやる必要ないのでそのままコピー。
コピーするsd_cardの中身は下のファイル構成
$ tree sd_card
>>>
sd_card
├── boot
│ ├── BOOT.BIN
│ ├── dpu.xclbin
│ ├── image.ub
├── platform_desc.txt
├── dpu.xclbin
├── README.txt
├── ultra96v2_oob.hwh
│ └── system.dtb
└── root
└── rootfs.tar.gz
sdカードに書きこみ用にsd.imgを作成
# sd.imgファイルを作成 truncate -s 8GiB sd.img sudo losetup -f >>> /dev/loop17 sudo losetup /dev/loop17 sd.img # sudo parted /dev/loop17 -s mklabel msdos -s mkpart primary fat32 0% 2GiB -s mkpart primary ext4 2GiB 100% sudo parted /dev/loop17 ### mklabel msdos mkpart primary fat32 0% 2GiB mkpart primary ext4 2GiB 100% q ### # 割り当ての確認 $ ls /dev/loop17* >>> /dev/loop17 /dev/loop17p1 /dev/loop17p2 sudo mkfs.vfat /dev/loop17p1 sudo mkfs.ext4 /dev/loop17p2 # マウント mkdir -p ./mnt/boot ./mnt/root sudo mount /dev/loop17p1 ./mnt/boot/ sudo mount /dev/loop17p2 ./mnt/root/ $ sudo cp sd_card/boot/* ./mnt/boot/ $ sudo tar -C ./mnt/root/ -xzvf sd_card/root/rootfs.tar.gz $ # 追加で必要なデータは、 ./mnt/root/home/root 以下に置く # sudo cp -r xilinx_vai_board_package ./mnt/root/home/root/ # sudo mkdir ./mnt/root/home/root/place # sudo cp -r seg_test_images ./mnt/root/home/root/place/ # sudo mkdir ./mnt/root/home/root/place/output sudo sync sudo umount ./mnt/boot sudo umount ./mnt/root sudo losetup -d /dev/loop17 # sd.imgに格納されてるか容量をcheck $ du -hs sd.img >>> 2.0G sd.img
あとはEtcherでsdカードに焼けばOK。
3.gtktermでultra96v2にログイン
VirtualBoxにUSBを認識させた。teratermのubuntu版「gtkterm」を使った
Ultra96v2ボードは1をoffに2をOnにしてSDカードのモード(JTAGではなく)にしておく。
まずVirtualBoxにUSB(JTAG)を認識させる。
・VirtualBox - 仮想マシンにUSBメモリを認識・マウント
# gtktermのインストール $ sudo apt-get install gtkterm # USBが認識されてるか確認 $ ls -l /dev/ttyUSB* >>> crw-rw---- 1 root dialout 188, 0 8月 28 17:11 /dev/ttyUSB0 crw-rw---- 1 root dialout 188, 1 8月 28 17:11 /dev/ttyUSB1 # ultra96v2ボードにアクセス(terminalで実行) $ gtkterm -p /dev/ttyUSB1 -s 115200
参考サイト
・How to format SD card for SD boot







































