SIGNATEの第4回AIエッジコンペに参加したので、そのレポートもかねたログを書こうと思う。
機械学習だけじゃなくて、ハードウェアもガチのコンペでした。
目次
1.ネットワークについて
2.C++のアプリケーションコードの工夫について
3.ハードウェアプラットフォームについて
1.ネットワークについて
1.1 使ったmodelと戦略
ModelはカスタマイズしやすいUnetを使った。ライブラリはkerasとtensorflowで、量子化前の変換作業のために以下のversionを使用。
・Keras==2.2.4
・tensorflow-gpu==1.13.1
Unetを選択したのはpretrainからfinetuneへのネットワークのカスタマイズとか、精度向上のためのカスタマイズがしやすかったから。
深さは512。処理速度が遅くならないようにモデル容量を少なめにしたので、メモリサイズは「14,067,237」。
このモデルでベンチマークを超える戦略をとった。
理由はこれでベンチマークを越えられれば、工夫・処理速度とかで、他の参加者とかなりの差別化になって、アドバンテージがとれると思ったから。
Yolov3とのモデルサイズの参考比較
| Yolov3 |
62,002,753 |
| Yolov3-tyny |
8,861,918 |
| 今回のUnet |
14,067,237 |
深さ512と1024の容量の比較
| 深さ |
容量 |
| 512 |
14,067,237 |
| 1024 |
31,055,557 |

今回のUnetのネットワーク図
他には深さ1024(メモリサイズ:31,055,557)にpruningなどの軽量化テクを使う方法も考えた。
あと、今回のコンペは、セグメンテーションタスクや前処理とかで、ハードウェアのPS側の演算も多くなると考えたので、softmaxを最終層に使った。
このおかげでハードウェア側でsoftmax演算IPを使って、DPUの使用率を多くできた。
採用しなかったアプローチ
採用しなかったアプローチは1024以上の深さのmodelを作り、pruningやDistillation(蒸留)でmodelを軽量化するアプローチ。
このアプローチはpruningやDistilliationなどの技術がハードウェア特有の色が濃いため、習熟度・難易度の面で時間的・開発コストがかかりすぎる(独学だと時間的にきつい)。
軽量化しないと、深さ1024のmodelはメモリが30,000,000以上になって処理速度に如実に反映されるので、この戦略は使わなかった。
1.2 コンパイル時のエラー対策を考慮したネットワーク構成のポイント
量子化の直前・直後で精度劣化やエラーになるレイヤー構成が存在したので、それらを除外してネットワークを構築した。
改善した点
1.「Conv2D => BatchNormarization(BN) => relu 」の順番のレイヤー構成の厳守
NG構成は「relu=>BN」で、コンパイル時エラーになる
x = Conv2D(filters = n_filters, kernel_size = (kernel_size, kernel_size),
kernel_initializer = 'he_normal', padding = 'same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
2. Decoder側にDropoutを使う
Decoder側(ConcatenateレイヤーやAddレイヤーを使う場所で)BNを使うと
量子化後の精度劣化につながる。
3. softmaxの前にConv2Dを使わずに、Conv2DTransposeを使った
今回はsoftmaxを使ったので、量子化するためには、softmax前にConv2Dレイヤー以外(Conv2Dtranspose, separateconv2D とか)を使う必要があった。
1.3 DPUと連携を考えてsoftmaxを使った
今回はハードウェアで、softmax演算IPを使えるように、unetでも最終層にsoftmaxを使った。
softmaxを使ったおかげで次のポイントが利点になった。
・DPUの使用率を増やせる・マルチスレッドで、PL, DPU演算, softmax演算の3つを並行処理できる
・sigmoidやreluよりsoftmaxの方が精度が高い
SoftmaxをUnetで使うための条件
vitisのDPUだと、SoftmaxをUnetで使う中で、試行錯誤の過程から以下のことが分かった。
・コンパイル時の制約として、softmaxの直前のレイヤーはConv2D以外(Conv2Dtranspose, SeparateConv2Dなど)
を使う必要がある
x=model.get_layer(index=-5).output
x = Conv2DTranspose(nClasses, kernel_size=1, use_bias=False)(x)
x = (Activation("softmax"))(x)
・Conv2DTransposeでは「use_bias=False」を指定しないと、DNNDKライブラリの「dpuGetOutputTensorScale()」出力が変化して、sfotmax出力でエラーになることがある
1.4. 精度向上のために工夫したテクニック
深さ512でIou=60%を超えるためには単純にネットワークを構築するだけでは難しく、精度向上のためネットワークに頼る以外の工夫をした。
使った主なテクニックは下の通り。
オリジナル画像(HEIGHT, WIDTH)の比率をなるべく維持した画像サイズでのリサイズ、アスペクト比を維持してのresize
=> Shape=(400, 680)でresizeすることで元画像のサイズ比率をkeepした。また、opencvでresizeでアスペクト比を維持するようにresizeした。これで(224, 224)のように正方形でresizeするよりも小さい物体(signal, pedestrian)の予測精度が上がった。
多分位置情報がresizeでlostすることが減ったためと思う。
ヒストグラム平均化で暗い画像(画素平均80以下)を明るくする前処理
=> 暗い画像の細かい部分の精度向上に若干つながった。暗い画像は画素が偏る特徴があるため、
「画素平均が低い=暗い画像」
として画素平均80未満の画像にヒストグラム平均化を使って明るくした。
def clahe(bgr):
lab = cv2.cvtColor(bgr, cv2.COLOR_BGR2LAB)
lab_planes = cv2.split(lab)
clahe = cv2.createCLAHE(clipLimit=6.0,tileGridSize=(8,8))
lab_planes[0] = clahe.apply(lab_planes[0])
lab = cv2.merge(lab_planes)
return cv2.cvtColor(lab, cv2.COLOR_LAB2BGR)
def NormalizeImageArr(path, H, W):
NORM_FACTOR = 255
img = cv2.imread(path, 1)
img = cv2.resize(img, (H, W), interpolation=cv2.INTER_NEAREST)
if img.mean()<80:
img = clahe(img)
img = img.astype(np.float32)
img = img/NORM_FACTOR
return img
augumatationでの学習
ノイズ系、contrast系、horizontal flipなど、位置を変化させずに済むaugumatationが一番効果があった。
車など上下反転することがない物体がある時はvertical flipは逆効果。
またaugumatationは一度にやらなくても少しずつ学習させた方が精度がだんだんと確実に上がっていくようだ。
以下の手順でaugumentationの学習をした。
| Epoch |
データセット |
IOU |
Augmentation |
| 100 |
CitySpacuies |
なし |
なし |
| 200 |
train:2143枚(コンペ用画像)、val:100枚(コンペ用画像) |
train=83.8%、Val = 74% |
なし |
| 200 |
train:2143枚(flipした画像のみ)、val:100枚(flipした画像のみ) |
train=76%、Val = 68% |
Horizontal flip (validationにも適用) |
| 100 |
train:4286枚、val:100枚 |
train=88.5%、Val = 75.8% |
Horizontal flip (valには適用なし) |
| 100 |
train:4286枚、val:100枚 |
train=89.2%、Val = 77.5% |
contrast系(valには適用なし) |
CitySpacesデータセットでpretrain
前回のコンペで前例があったので真似したら、精度がかなり上がった。
Residual構造やセグメンテーションに有利なサブレイヤーを追加するなどを試したが、深さ512だとモデルの表現力に限界があり、ほとんど効果がなかった。またMultiply演算を使うSENetなどもコンパイル時にエラーが出るなどの制約がある部分で精度向上ができなかったのがきつかった。
PDCAで学んだ点は何らかの精度向上のロジック・仮説がないまま闇雲に技術を駆使してもほとんどの工夫は無駄になるということ。
1.5.最後のネットワークのIouなどの結果
最終的にmodelサイズが「14,067,237」の状態でIou=61%(ほど)を達成した。
2.C++のアプリケーションコードの工夫について
処理速度やハードウェアの性能を引き出すためにC++で特に注力したポイントは2つ。
2.1 計算量の削減
今回はPS側の計算が多く、マルチスレッドを3つ使用したため、冗長なコードの削減・簡略化はかなり処理速度に効果がでた。
特に以下のような書き換えで、改善箇所1つにつき、30msほど速くなった。
・forループの効率化
・無駄な関数、その関数の無駄な呼び出しの削除
・決まった値の定数化
2.2. ハードウェアの性能を引き出すために、3つのマルチスレッド処理
今回は前処理やセグメンテーションでのforループなど、DPU演算以外のPS演算の使用率が多かっ たので、マルチスレッドを3つにすることで、30~50msほど早くなった。
下はDPUパラメータ(B1152, 「DSP48 USAGE=LOW」など)の時のマルチスレッド2つの時と3つの時の速度の違い
| マルチスレッド個数 |
画像1枚の平均処理速度(ms) |
| 2こ |
1061 |
| 3こ |
1007 |
3.3 PSとPL(DPU演算)のDPU演算とsoftmax演算の3つをマルチスレッドで並行処理してさらなる処理速度の向上
本来のマルチスレッドは「PS・PL」を並行処理することで処理速度を上げるのが目的だが、 今回はDNNDKライブラリを使用しているため、PLは
・DPU演算
・softmax演算
で使うメソッドが独立している。
| DPU演算メソッド |
dpuRunTask() |
| softmax演算メソッド |
dpuRunSoftmax() |
このため今回は
・PS演算
・DPU演算
・softmax演算
の3つをマルチスレッドの並行処理の対象とした。DPU演算とsoftmax演算の両方に非同期処理std::lock_guard lock(mtx_)を用いることで、
DPU演算とsoftmax演算を並行ことができ、マルチスレッドでさらなる処理速度向上が可能になった。
PS・DPU演算(PL)・spftmax演算(PL)の3つを並行処理したマルチスレッド用関数 (main_thread())の抜粋(重要箇所のみ)
#include <thread>
#include <opencv2/opencv.hpp>
#include <opencv2/core.hpp>
#include <dnndk/dnndk.h>
#include <mutex>
std::mutex mtx_;
〜〜
〜〜
int main_thread(DPUKernel *kernelConv, int s_num, int e_num, int tid){
assert(kernelConv);
DPUTask *task = dpuCreateTask(kernelConv, DPU_MODE_NORMAL);
〜〜〜
int cnt=0;
for(cnt=s_num; cnt<=e_num; cnt+=BLOCK_SIZE){
for(int i=0; i<BLOCK_SIZE;i++){
if(cnt+i>e_num) break;
Mat img;
resize(input_image[i], img, for_resize, INTER_NEAREST);
Mat clahe_img = img;
if((int)mean(img)[0] < 80) {
clahe_img = clahe_preprocess(img);
}
float *softmax = new float[outWidth*outHeight*outChannel]
set_input_image(task, outWidth, clahe_img);
{
std::lock_guard<std::mutex> lock(mtx_);
dpuRunTask(task);
}
{
std::lock_guard<std::mutex> lock(mtx_);
int8_t *outAddr = (int8_t *)dpuGetOutputTensorAddress(task, CONV_OUTPUT_NODE);
dpuRunSoftmax(outAddr, softmax, outChannel,outSize/outChannel, outScale);
}
PostProc(softmax, outHeight, outWidth, outChannel, image_file_name[i].c_str());
delete[] softmax;
}
}
dpuDestroyTask(task);
return 0;
}

3マルチスレッドでPS・DPU演算・softmax演算を並行処理
3.ハードウェアプラットフォームについて
3.1 開発環境
QiitaのVitis-AI開発環境のサイトを参考にした。Vitis-AI-Runtimeライブラリは使わなかったので、DNNDKライブラリベースで開発をした。
3.2 DPUのハードウェアプラットフォーム構築上の工夫について
Vitis-AI環境設定のチュートリアルと第2回のエッジAIコンペの資料(以下:参考資料)を主に参考に、チュートリアルのプラットフォームに改善を加え構築した。
3.2.1 softmax演算IPの活用
なるべくDPU演算を活用するためにsfotmax演算IPを活用。
UnetでConv2DTrasposeを使い、modelとの連携を考慮して、softmax演算を使った。
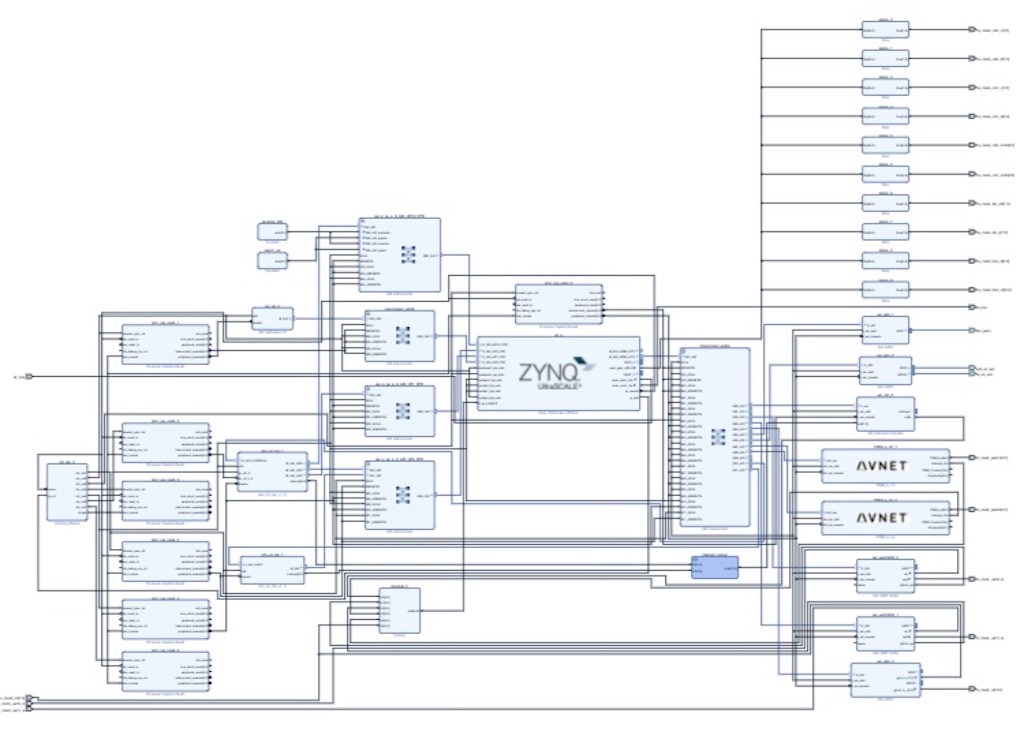
Softmax演算を含んだプラットフォーム(不要なIP削除ずみ)
3.2.2 プラットフォームの構築・改良
DNNDKベースでの開発のため、参考資料をヒントに、Visits-AIプラットフォームの
チュートリアルをメインに改良した。
はじめはDPUを搭載したプラットフォームを参考資料の
・softmaxと連携したB1600のDPUの搭載・DPUの周波数250MHz
の条件で動くことをはじめの目標にした。
そのためにまずチュートリアルのプラットフォームに
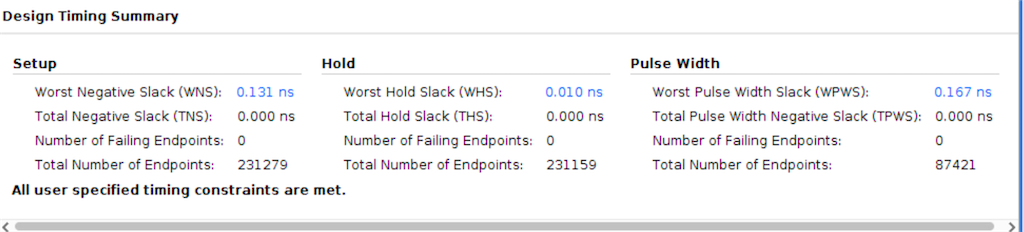
をして、WNS=0.027でプラットフォームを構築。
今回はmodelの使用のためには「DepthwiseConv」をEnableにする必要性からパラメータと周波数に変更を加えた。
3.3 DPUパラメータと周波数
今回はDPUパラメータの「DepthwiseConv」をEnableにする必要があったため、パラメータがデカすぎて周波数が大きいとリブートしてしまうので、B1600で250MHzでのDPUパラメータでの搭載は出来なかった。
「DepthwiseConv」はB1600で「3292」のLUTを使用することから、DPUパラメータのリソースを参考資料よりかなり減らす必要があった。
特に今回のmodelではconvolution層を多用するため、
「Channel Augumetation」をEnableにしないと、「DSP48 Usage」をHighの時でもかなり処理速度が低下するため、
・「Channel Augmentaion」をEnable・「DepthWiseConv」をEnable
を必須条件にした。
結果的に、周波数225MHz以上で「DSP48 USAGE」をHIGHにした状態だとリブートしてしまったので、最終的に周波数200MHz、かつ以下のパラメータでDPUを搭載した。
| 周波数 |
200MHz |
| DPU |
B1600(ReLU+ReLU6) |
| Channel Augmentation |
Enable |
| DepthWiseConv |
Enable |
| PoolAverage |
Disnable |
| DSP48 USAGE |
HIGH |
| RAM USAGE |
LOW |
| Softmax |
Enable |
リソースの関係上これ以上の周波数向上はできなかった。
3.4 implとsynthストラテジで処理速度の向上
今回のDPUパラメータに周波数200MHzでは、DPUの性能を引き出すには周波数が足りないので、ストラテジの組み合わせで処理速度が向上できないか、fixstarsのサイトを参考にいくつか試した。
「高集積度FPGA設計ガイド」によるとリソースが多いほど集積度を低くしないと、リソースの使用度が難しくなるらしい。
今回はDPUのリソースが多かったため、集積度が低くなるように、分散させる系の以下のストラテジの組み合わせを選択したことで35msほど早くなった。
| impl |
Congestion_SpreadLogic_high |
| Synth |
Flow_AreaOptimized_high |
| WNS |
0.131 ns |
SSIに分散するストラテジ「impl : Congestion_SSI_SpreadLogic_low」も試したが、SSIは消費電力は低いものの、集積度が高いので、上の組み合わせの方が処理性能は高かった。
このストラテジーの組み合わせ、B1600、周波数200MHZなどで制約を満たしたDPUを搭載した。
PSと比較してDPUとsoftmaxの使用率は以下の通りになった。
| PS & PL Tototal |
93% |
| DPU |
43% |
| Softmax |
6% |

今回の消費電力レポート

参考資料
・
vitis-AI platform site(qiita)・DPU-TRD
・Xilinx GitHub Vitis-AI-TUTORIAL
・Vivado の合成/インプリメンテーションストラテジを変えてみる(WNS・走行時間編)
・第2回AIエッジコンペ資料
・Zynq DPU v3.2ガイド
・高集積度 FPGA 設計手法 ガイド