yolov5とDeepsortとかいうtrackingのアルゴリズムを使ってtrackingの物体検出をしてみた。
最終的にpythonのGUIツールtkinterでマルチスレッド化して動かした。
全体像

備忘録として使った技術をまとめてく。
目次
1.yolov5
2.trackingアルゴリズム「DeepSort」
3.GUIツールの「tkinter」
4.pythonでマルチスレッド
5.出力結果
1.yolov5
yolov5はDarknetを使ってない。
今回はmac上で動かして、Pytorch のyolov5を使った。
yolov5は
Small(YOLOv5s) => Medium(YOLOv5m) => Large(YOLOv5l)=> Xlarge(YOLOv5x)
の順で大きさと精度が増してくらしい。


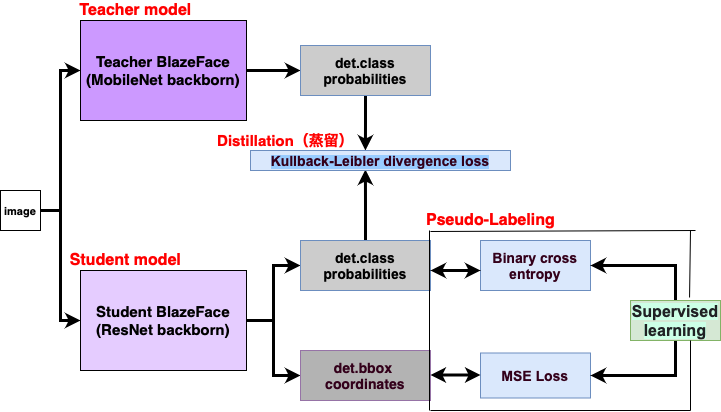
2.trackingアルゴリズム「DeepSort」
DeepSORTの
アーキテクチャは物体検出とト
ラッキングに分かれてて、yolov5の推論後に、物体検出のbboxに番号をつけて検出物をtrackingする。

ここのgithubを参考にした
・Yolov5_DeepSort_Pytorch
・yolov4-deepsort
DeepSortとyolov5のtrackingコードの一部。
yolov5_tracking.py(の一部)
import sys
from pathlib import Path
import cv2, os
import numpy as np
import time
import torch
import torch.backends.cudnn as cudnn
import PIL.Image, PIL.ImageTk
from multiprocessing import Queue
def load_model(weights, device, half=False):
global deepsort
cfg = get_config()
cfg.merge_from_file('Deepsort/configs/deep_sort.yaml')
deepsort = DeepSort(cfg.DEEPSORT.REID_CKPT,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True)
yolov5 = attempt_load(weights, map_location=device)
if half:
yolov5.half()
return yolov5
def yolov5_detection(q:Queue, opt, save_vid=False, show_vid=False, tkinter_is=False):
initialize()
weights, source, imgsz, conf_thres, iou_thres = opt.weights, opt.source, opt.imgsz, opt.conf_thres, opt.iou_thres
save_txt, classes, agnostic_nms, augment = opt.save_txt, opt.classes, opt.agnostic_nms, opt.augment
nosave, exist_ok = opt.nosave, opt.exist_ok
w = weights[0] if isinstance(weights, list) else weights
classify, suffix, suffixes = False, Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', '']
check_suffix(w, suffixes)
pt, onnx, tflite, pb, saved_model = (suffix == x for x in suffixes)
stride, names = 64, [f'class{i}' for i in range(1000)]
yolov5 = load_model(weights, device, half=False)
stride = int(yolov5.stride.max())
names = yolov5.module.names if hasattr(yolov5, 'module') else yolov5.names
vid_path, vid_writer = None, None
if webcam:
cudnn.benchmark = True
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)
bs = 1
if pt and device.type != 'cpu':
yolov5(torch.zeros(1, 3, *imgsz).to(device).type_as(next(yolov5.parameters())))
dt, seen = [0.0, 0.0, 0.0], 0
t0 = time.time()
for frame_idx, (path, img, im0s, vid_cap) in enumerate(dataset):
t1 = time_sync()
img = preprocess_img(img, device, half=half)
pred = yolov5(img, augment=opt.augment)[0]
pred = non_max_suppression(
pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_sync()
for i, det in enumerate(pred):
p, s, im0 = path, '', im0s
s += '%gx%g ' % img.shape[2:]
save_path = str(Path(project) / Path(p).name)
annotator = Annotator(im0, line_width=2, pil=not ascii)
deepsort, annotator, s = deepsort_detection(annotator, det, img, im0, names, s)
print('%sDone. (%.3fs)' % (s, t2 - t1))
im0 = annotator.result()
if show_vid:
cv2.imshow(p, im0)
if cv2.waitKey(1) == ord('q'):
raise StopIteration
elif save_vid:
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release()
if vid_cap:
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else:
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
elif tkinter_is:
im_rgb = cv2.cvtColor(im0, cv2.COLOR_BGR2RGB)
im_rgb = cv2.resize(im_rgb, (1280, 720))
q.put(im_rgb)
print('Done. (%.3fs)' % (time.time() - t0))
pythonの
GUIツールはありすぎるけど
tkinterが1, 2位の人気があるっぽい。(2021/09)
Google trandで一年間の推移を見ても全ての国で人気が衰えてないし、グラフ化してもはっきりわかる。


yolov5_tracking.pyで取得した画像をtkinterで表示。
tkinter_app.py
import tkinter as tk
from tkinter import ttk
import cv2
import PIL.Image, PIL.ImageTk
from tkinter import font
import time
from multiprocessing import Queue
class Application(tk.Frame):
def __init__(self,master, q:Queue, video_source=0):
super().__init__(master)
self.master.geometry("1280x768")
self.master.title("Tkinter with Video Streaming and Capture")
self.q = q
self.font_setup()
self.vcap = cv2.VideoCapture( video_source )
self.width = self.vcap.get( cv2.CAP_PROP_FRAME_WIDTH )
self.height = self.vcap.get( cv2.CAP_PROP_FRAME_HEIGHT )
self.create_widgets()
self.create_frame_button(self.master)
self.delay = 15
self.update()
def font_setup(self):
self.font_frame = font.Font( family="Meiryo UI", size=15, weight="normal" )
self.font_btn_big = font.Font( family="Meiryo UI", size=20, weight="bold" )
self.font_btn_small = font.Font( family="Meiryo UI", size=15, weight="bold" )
self.font_lbl_bigger = font.Font( family="Meiryo UI", size=45, weight="bold" )
self.font_lbl_big = font.Font( family="Meiryo UI", size=30, weight="bold" )
self.font_lbl_middle = font.Font( family="Meiryo UI", size=15, weight="bold" )
self.font_lbl_small = font.Font( family="Meiryo UI", size=12, weight="normal" )
def create_widgets(self):
self.frame_cam = tk.LabelFrame(self.master, text = 'Camera', font=self.font_frame)
self.frame_cam.place(x = 10, y = 10)
self.frame_cam.configure(width = self.width+30, height = self.height+50)
self.frame_cam.grid_propagate(0)
self.canvas1 = tk.Canvas(self.frame_cam)
self.canvas1.configure( width= self.width, height=self.height)
self.canvas1.grid(column= 0, row=0,padx = 10, pady=10)
def create_frame_button(self, root):
self.frame_btn = tk.LabelFrame(root, text='Control', font=self.font_frame)
self.frame_btn.place(x=10, y=650 )
self.frame_btn.configure(width=self.width, height=120 )
self.frame_btn.grid_propagate(0)
self.btn_close = tk.Button( self.frame_btn, text='Close', font=self.font_btn_big )
self.btn_close.configure( width=15, height=1, command=self.press_close_button )
self.btn_close.grid( column=1, row=0, padx=20, pady=10 )
def update(self):
frame = self.q.get()
self.photo = PIL.ImageTk.PhotoImage(image = PIL.Image.fromarray(frame))
self.canvas1.create_image(0,0, image= self.photo, anchor = tk.NW)
self.master.after(self.delay, self.update)
def press_close_button(self):
self.master.destroy()
self.vcap.release()
self.canvas.delete("o")
c++でマルチスレッドをしたことがあるけど、phthonでしてみた。
yolov5で取得したimgを
tkinterで出力する。
yolov5_tracking.pyのProcess部分
elif tkinter_is:
im_rgb = cv2.cvtColor(im0, cv2.COLOR_BGR2RGB)
im_rgb = cv2.resize(im_rgb, (1280, 720))
q.put(im_rgb)
tkinter_app.pyでyolov5_tracking.pyを取得して、canvasにplotする部分
def __init__(self,master, q:Queue, video_source=0):
super().__init__(master)
self.master.geometry("1280x768")
self.master.title("Tkinter with Video Streaming and Capture")
self.q = q
def update(self):
frame = self.q.get()
self.photo = PIL.ImageTk.PhotoImage(image = PIL.Image.fromarray(frame))
self.canvas1.create_image(0,0, image= self.photo, anchor = tk.NW)
self.master.after(self.delay, self.update)
最終的にtkinter_app.py とyolov5_tracking.pyをマルチスレッド化して動かす
main.py
from multiprocessing import Process, Queue
def tkapp_thread(q):
import tkinter as tk
from tkapp_thread import Application
root = tk.Tk()
app = Application(root, q, video_source=0)
app.mainloop()
def yolov5_thread(q):
from yolov5_detect import yolov5_detection
from option_parser import get_parser
opt = get_parser()
yolov5_detection(q, opt, save_vid=False, show_vid=False, tkinter_is=True)
if __name__ == '__main__':
q = Queue()
p1 = Process(target = tkapp_thread, args=(q,))
p2 = Process(target = yolov5_thread, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()
5.出力結果
Yolov5 + DeepSort + multi-thread +
tkinter + 動画
で出力した結果はこちら
出力1

出力2

CPUのMac上だとかなり遅いけど、精度はかなりいい。
DeepSort + multi-thread + Tkinter
の組み合わせは面白かった。