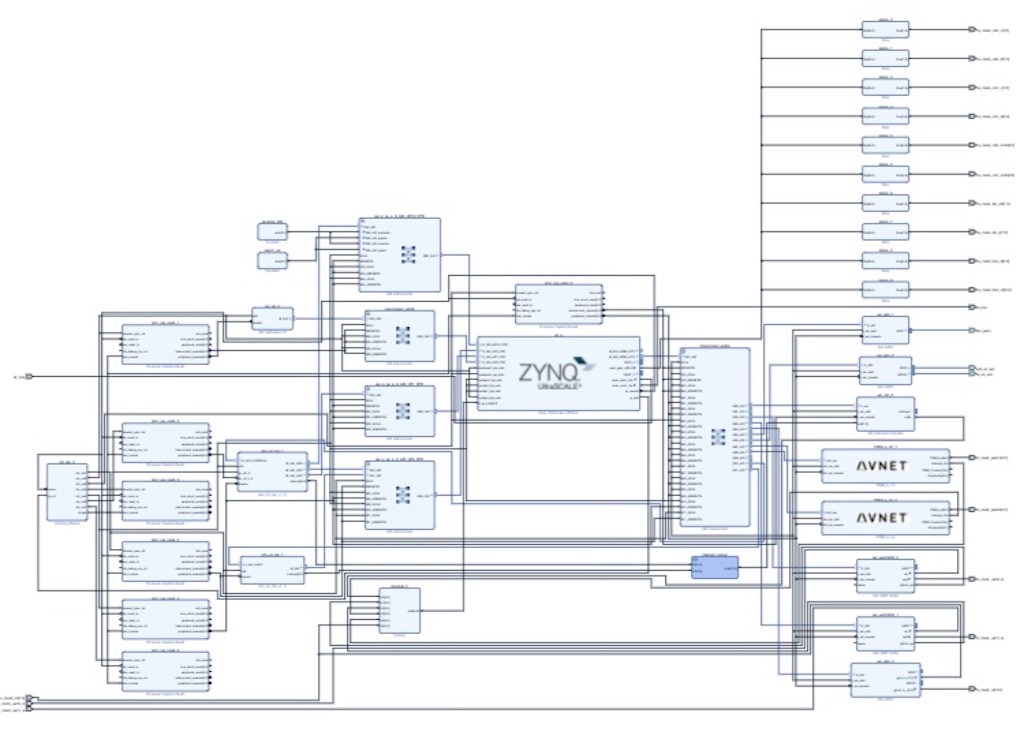
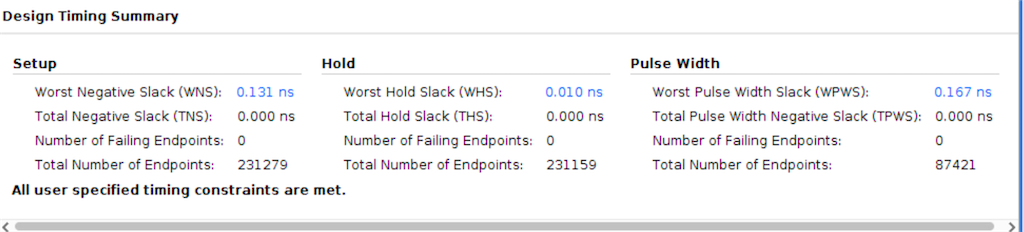
2021/01月の記録です。
Codilityの難易度
「PAINLESS」<「RESPECTABLE」<「AMBITIOUS」
の順でむずくなってる
まずは分割統治法で簡単なの解いてみて、test=> 汎用的なコード書くこと
エラーはpythonでも、javaとかc++でもググって応用してみる。特にjavaは回答が充実してるのでjavaからの応用はおすすめ

Iteration:BinaryGap(PAINLESS)
my solution
def reset(ones, zeros): ones = 1 zeros = 0 return ones, zeros def solution(N): binari = bin(N)[2:] ones, zeros = 0, 0 lenth = [] for i, val in enumerate(binari): if val==str(1): ones+=1 else: zeros+=1 if ones==2: lenth.append(zeros) ones, zeros = reset(ones, zeros) return max(lenth) if lenth else 0
smart code solution
def solution(N): N = str(bin(N)[2:]) count = False gap = 0 max_gap = 0 for i in N: if i == '1' and count==False: count = True if i == '0' and count == True: gap += 1 if i == '1' and count == True: max_gap = max(max_gap, gap) gap = 0 return max_gap
Array:CyclicRotation(PAINLESS)
My solutiondef solution(A, K): n = len(A) for _ in range(K): last = A[-1] del A[-1] A=[last]+A return A
smart solution
def solution(A, K): # write your code in Python 2.7 l = len(A) if l < 2: return A elif l == K: return A else: B = [0]*l for i in range(l): B[(i+K)%l] = A[i] return B
Time Complexity:TapeEquilibrium(PAINLESS)
My solutiondef solution(A): diff = float('inf') for i in range(1, len(A)-1): s1 = sum(A[:i]) s2 = sum(A[i:]) diff = min(diff, abs(s1-s2)) return diff
smart solution
def solution(A): total, minimum, left = sum(A), float('inf'), 0 for a in A[:-1]: left += a minimum = min(abs(total - left - left), minimum) return minimum
Counting Elements:MaxCounters(RESPECTABLE)
My solutiondef solution(N, A): arr = [0]*N maxim = max(A) for val in A: if val == maxim: arr = [max(arr)]*N else: arr[val-1]+=1 return arr
smart solution
def solution2(N, A): counters = [0] * N for el in A: if el <= N: counters[el - 1] += 1 else: counters = [max(counters)] * N return counters
CoderByte
CoderByte Challenge Libarary
Easy & Algorithm
Find Intersection
FindIntersection(strArr) read the array of strings stored in strArr which will contain 2 elements: the first element will represent a list of comma-separated numbers sorted in ascending order, the second element will represent a second list of comma-separated numbers (also sorted). Your goal is to return a comma-separated string containing the numbers that occur in elements of strArr in sorted order. If there is no intersection, return the string false.
Input: ["1, 3, 4, 7, 13", "1, 2, 4, 13, 15"] Output: 1,4,13
def FindIntersection(strArr): st1 = list(map(int, strArr[0].split(', '))) st2 = list(map(int, strArr[1].split(', '))) string = [] for s in st1: if s in st2: string.append(str(s)) return ','.join(string) if string else False
Codeland Username Validation
Have the function CodelandUsernameValidation(str) take the str parameter being passed and determine if the string is a valid username according to the following rules:1. The username is between 4 and 25 characters.
2. It must start with a letter.
3. It can only contain letters, numbers, and the underscore character.
4. It cannot end with an underscore character.
If the username is valid then your program should return the string true, otherwise return the string false.
# sample1 input: "aa_" Output: false #sample2 Input: "u__hello_world123" Output: true
def CodelandUsernameValidation(strParam): stack = [] if len(strParam)<4 or len(strParam)>25: return 'false' if not strParam[0].isalpha() or strParam[-1]=='_': return 'false' for x in list(strParam): if x.isalpha() or x=='_' or x.isdigit(): stack.append(x) return 'true' if stack else 'false'
Questions Marks
Have the function QuestionsMarks(str) take the str string parameter, which will contain single digit numbers, letters, and question marks, and check if there are exactly 3 question marks between every pair of two numbers that add up to 10. If so, then your program should return the string true, otherwise it should return the string false. If there aren't any two numbers that add up to 10 in the string, then your program should return false as well.For example: if str is "arrb6???4xxbl5???eee5" then your program should return true because there are exactly 3 question marks between 6 and 4, and 3 question marks between 5 and 5 at the end of the string.
# sample1 Input: "aa6?9" Output: false #sample2 Input: "acc?7??sss?3rr1??????5" Output: true
def QuestionsMarks(strParam): question = [] total = 0 for s in list(strParam): if s.isdigit() and len(question)<3: total += int(s) elif s.isdigit() and len(question)>3: total += int(s) if total==10: return 'true' elif s=='?': question.append(s) return 'false'
Longest Word
Have the function LongestWord(sen) take the sen parameter being passed and return the largest word in the string. If there are two or more words that are the same length, return the first word from the string with that length. Ignore punctuation and assume sen will not be empty.# sample1 Input: "fun&!! time" Output: time #sample2 Input: "I love dogs" Output: love
def LongestWord(sen): stack = {} string='' for s in list(sen): if s.isalpha(): string +=s else: stack[string]=len(string) string='' stack[string]=len(string) return max(stack, key=stack.get)
First Factorial
Have the function FirstFactorial(num) take the num parameter being passed and return the factorial of it. For example: if num = 4, then your program should return (4 * 3 * 2 * 1) = 24. For the test cases, the range will be between 1 and 18 and the input will always be an integer.# sample1 Input: 4 Output: 24 #sample2 Input: 8 Output: 40320
def FirstFactorial(num): factorial = 1 for i in range(num, 0, -1): factorial *= i return factorial
Min Window Substring(Mediam)
#algorithm #FacebokMinWindowSubstring(strArr) take the array of strings stored in strArr, which will contain only two strings, the first parameter being the string N and the second parameter being a string K of some characters, and your goal is to determine the smallest substring of N that contains all the characters in K. For example: if strArr is ["aaabaaddae", "aed"] then the smallest substring of N that contains the characters a, e, and d is "dae" located at the end of the string. So for this example your program should return the string dae.
Another example: if strArr is ["aabdccdbcacd", "aad"] then the smallest substring of N that contains all of the characters in K is "aabd" which is located at the beginning of the string. Both parameters will be strings ranging in length from 1 to 50 characters and all of K's characters will exist somewhere in the string N. Both strings will only contains lowercase alphabetic characters.
Input: ["ahffaksfajeeubsne", "jefaa"] Output: aksfaje
def MinWindowSubstring(strArr): N = list(strArr[0]) K = list(strArr[1]) Ks = list(strArr[1]).copy() string = '' for i, s in enumerate(N): if s in K: K.remove(s) string +=s if not K: break elif string: string +=s submit = '' for r in string[::-1]: if r in Ks: Ks.remove(r) submit += r if not Ks: return submit[::-1]