I created CNN+LSTM model that has Attention layers in LSTM side.
CNN is role of encoder and LSTM is one of decoder.
Here, I'll write this as log of my analysis about how to use CNN output as LSTM input, and Attentions that are 'Self-Attenttion' and 'Source-Target Attention'.
This is just like my dialy, thus it's simple and short.
Contents
1.How to use CNN output as LSAM input
2.Analysis result of Attention
3.Self-Attention
4.Source-Target Attention
5.Summary
1.How to use CNN output as LSTM input
This time, input data are images and aim is meta label classification such as image colors and shape types.First, input image to CNN-encoder and use its output to LSTM input.
CNN+LSTM Overall

CNN output and LSTM input part
"""params""" device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') LSTM_UNITS = 200 embed_size = 1024 H = W = 224 in_size = 3 input_size = (1, in_size, H, W) inp1 = torch.rand(input_size, dtype=torch.float32).to(device) """CNN encoder""" avgpool = nn.AdaptiveAvgPool2d(1) lstm = nn.LSTM(embed_size, LSTM_UNITS, bidirectional=True, batch_first=True) x = self.cnn(x) print(x.shape) # torch.Size([1, 512, 14, 14]) x = avgpool(x) # torch.Size([1, 512, 1, 1]) x = torch.reshape(x, (1, embed_size, 1, 1)) b,f,_,_ = x.shape embedding = x.reshape(1,b,f) print(embedding.shape) #torch.Size([1, 1, 1024]) """LSTM decoder """ lstm.flatten_parameters() h_lstm1, (hidden1, cell1) = lstm1(embedding) print(h_lstm1.shape, hidden1.shape) #torch.Size([1, 1, 400]) torch.Size([2, 1, 200])
2.Analysis result of Attention
Attention is divided to Self-Attention and Source-Target Attention.Self-Attention has only 1 input and can be used for many filed and easy to customized.
Source-Target Attention has 2 input that's input and memory(input is as query, memory is keys and value).
It is mainly for sequence data and text emmbadding vector, as mainly used at after LSTM output.
This time, I analize and used the 2 Attentions to LSTM.
3.Self-Attention
Self-Attention is mainly for NLP and use for Network mainly like LSTM, seq2seq and Transformer.
But recent day, as improved ML, Attention layers is used to CNN (image classification).
I'll use Attention layer for CNN another time, and this time I used for LSTM for improving accuracy.
Self-Attention stracture

class SelfAttention(nn.Module): def __init__(self, lstm_dim): super(SelfAttention, self).__init__() self.lstm_dim = lstm_dim *2 self.attn_weight = nn.Sequential( nn.Linear(lstm_dim *2, lstm_dim *2), nn.Tanh(), nn.Linear(lstm_dim *2, lstm_dim *2) ) def forward(self, lstm_output): attn_weight = self.attn_weight(lstm_output) attn_weight = F.softmax(attn_weight, dim=2) feats = torch.cat([lstm_output, attn_weight], 2) return feats.squeeze(0) LSTM_UNITS = 200 num_cls = 12 input_size = (1, 1, 400) # function and class selfattension = SelfAttention(LSTM_UNITS) attention_linear = nn.Linear(LSTM_UNITS*4, num_cls) final_activate = nn.Softmax(dim=1) # inputs hidden = torch.rand(input_size, dtype=torch.float32).to(device) print(hidden.shape) # torch.Size([1, 1, 400]) # in LSTM, after "hidden = h_lstm1 + h_lstm2" hidden = selfattension(hidden) print(hidden.shape) # torch.Size([1, 800]) output = attention_linear(hidden) output = final_activate(output) print(output.shape) # torch.Size([1, 12])
In LSTM, Self-Attention is mainly placed around LSTM's final layer.
I reffed Kaggle sample use and PyTorch github.
4.Source-Target Attention
This time, I used this at after LSTM's output.
In Transformer, use many "Source-Target Attention" and it called as "Multi-head Attention"
"Source-Target Attention" is harder to customize more than 'Self-Attenttion'. but it depends on technique and idea.(up to you)
"Source-Target Attention" structure

def source_target_attention(lstm_output, final_state): lstm_output = lstm_output.permute(1, 0, 2) # keys querys = final_state.squeeze(0) # query logits = torch.bmm(lstm_output, querys.unsqueeze(2)).squeeze(2) attn_weights = F.softmax(logits, dim=1) new_hidden_state = torch.bmm(lstm_output.transpose(1, 2), # value attn_weights.unsqueeze(2)).squeeze(2) return new_hidden_state # LSTM outputs lstm_output = torch.rand((1, 1, 400), dtype=torch.float32) hidden1 = torch.rand((2, 1, 200), dtype=torch.float32) # in LSTM, #h_lstm1, (hidden1, cell1) = self.lstm1(embedding) hidden1 = hidden1.reshape(1, 1, 400) lstm_output = source_target_attention(lstm_output, hidden1).unsqueeze(0) print(lstm_output.shape) # torch.Size([1, 1, 400])
5.Summary
this time I realized that CNN-LSTM with Attention is good for image label classification not only for NLP task.
good accuracy is due to coverting image to sequence data.(3d to 1d).
I roughly draw entire this time network image which show where I set the 2 Attentions as follows
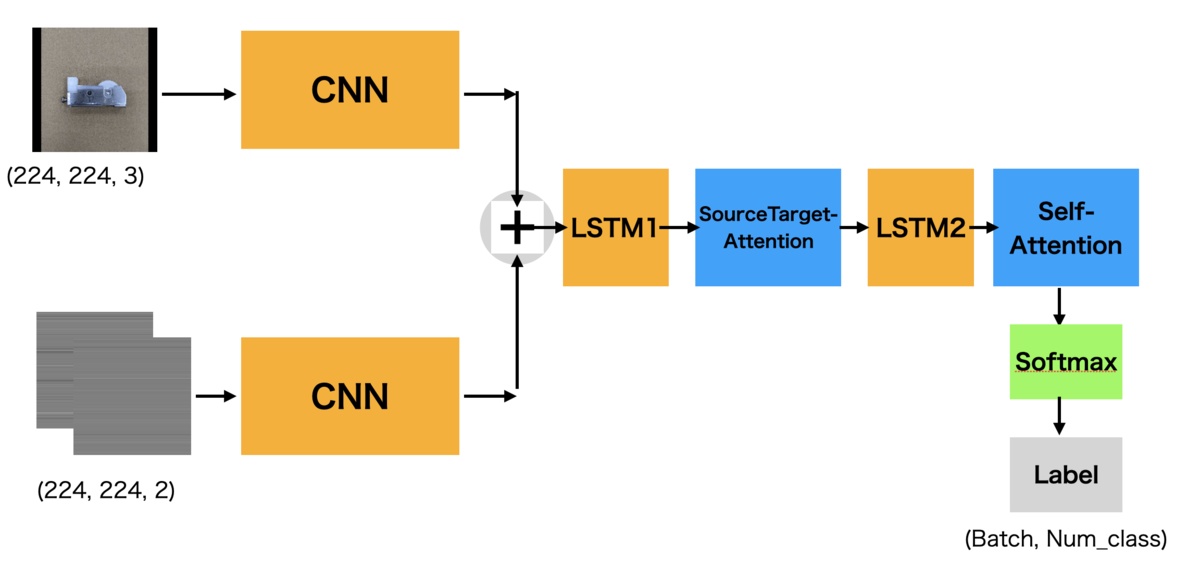
and this time better loss and activation are
Loss :
nn.CrossEntropyLoss()Final activation :
nn.Softmax(dim=1)task was to classify color label in 11 colors and shape label in 2 shape type.(meta data label).
if you use this for NLP task, loss and final activation should be as follows.
Accuracy is almost as good as I expected. If I find better architecture, will improve more.
Reference site
・Attention is all you need(jp)・ self attention 】簡単に予測理由を可視化できる文書分類モデルを実装する