OTA-loss とかOCcostとか話題になってる昨今に絡んで、「Sinkhorn」とかいう手法が気になってた。
何でもlossかなんかのmatrixを最適化する手法でSinkhorn lossとかいうのもある。Yolov7を使ってる最中だったので、なんとかYolov7にSinkhornを使ってみたかった。
なので、物体検出の最新版Yolov7にSinkhorn使って検証してみた。その備忘録。
目次
1. Sinkhornとは
2. Sinkhornと Yolov7のOTA-lossの融合
3. 検証結果
1. Sinkhornとは
Sinkhornとは二つの変数で求めたcost matrixを最小化する手法で最適化輸送問題に使われる。簡単にどう使うかというとpredictionとground truthで求めたlossをcost matrixとして使って、Sinkhornで最適化して、lossをさらに改善しようという話。
predictionとground truthを確立分布とみなして同じに近づけるので、Kullback-Leibler Divergence lossと仕組みは近いと思う。
Sinkhornとlossの仕組み
細かい説明はした記事を参照。
・OTA(Optimal Transport Assignment for Object Detection)
・最適化輸送問題
Sinkhorn loss
import torch import torch.nn as nn # Adapted from https://github.com/gpeyre/SinkhornAutoDiff class SinkhornDistance(nn.Module): def __init__(self, model, eps, max_iter, reduction='none'): super(SinkhornDistance, self).__init__() self.device = next(model.parameters()).device self.eps = eps self.max_iter = max_iter self.reduction = reduction def forward(self, cost, pred, truth): ''' We can easily see that the optimal transport corresponds to assigning each point in the support of pred(x) to the point of truth(y) ''' x, y = pred, truth # The Sinkhorn algorithm takes as input three variables : C = cost # Wasserstein cost function x_points = x.shape[-2] y_points = y.shape[-2] if x.dim() == 2: batch_size = 1 else: batch_size = x.shape[0] # both marginals are fixed with equal weights mu = torch.empty(batch_size, x_points, dtype=torch.float, requires_grad=False, device=self.device).fill_(1.0 / x_points).squeeze() nu = torch.empty(batch_size, y_points, dtype=torch.float, requires_grad=False, device=self.device).fill_(1.0 / y_points).squeeze() u = torch.zeros_like(mu) v = torch.zeros_like(nu) # To check if algorithm terminates because of threshold # or max iterations reached actual_nits = 0 # Stopping criterion thresh = 1e-1 # Sinkhorn iterations for i in range(self.max_iter): u1 = u # useful to check the update u = self.eps * (torch.log(mu+1e-8) - torch.logsumexp(self.M(C, u, v), dim=-1)) + u v = self.eps * (torch.log(nu+1e-8) - torch.logsumexp(self.M(C, u, v).transpose(-2, -1), dim=-1)) + v err = (u - u1).abs().sum(-1).mean() actual_nits += 1 if err.item() < thresh: break U, V = u, v # Transport plan pi = diag(a)*K*diag(b) pi = torch.exp(self.M(C, U, V)) # Sinkhorn distance cost = torch.sum(pi * C, dim=(-2, -1)) if self.reduction == 'mean': cost = cost.mean() elif self.reduction == 'sum': cost = cost.sum() return cost #, pi, C def M(self, C, u, v): "Modified cost for logarithmic updates" "$M_{ij} = (-c_{ij} + u_i + v_j) / \epsilon$" return (-C + u.unsqueeze(-1) + v.unsqueeze(-2)) / self.eps @staticmethod def ave(u, u1, tau): "Barycenter subroutine, used by kinetic acceleration through extrapolation." return tau * u + (1 - tau) * u1
2. Sinkhornと Yolov7のOTA-lossの融合
Yolov7のOTA-lossに Sinkhornを使ってみた。object lossとiou lossは3次元でなかったり、相性が悪かったので、class lossだけに使うことにした。
Sinkhornを使ったyolov7のOTA-loss
class ComputeLossOTA: if self.use_cost: lcls_cost = self.BCEcls(ps[:, 5:], t) lcls += self.sinkhorn(cost=lcls_cost.unsqueeze(2), pred=ps[:, 5:].unsqueeze(2), truth=t.unsqueeze(2)) else: lcls += self.BCEcls(ps[:, 5:], t) # BCE
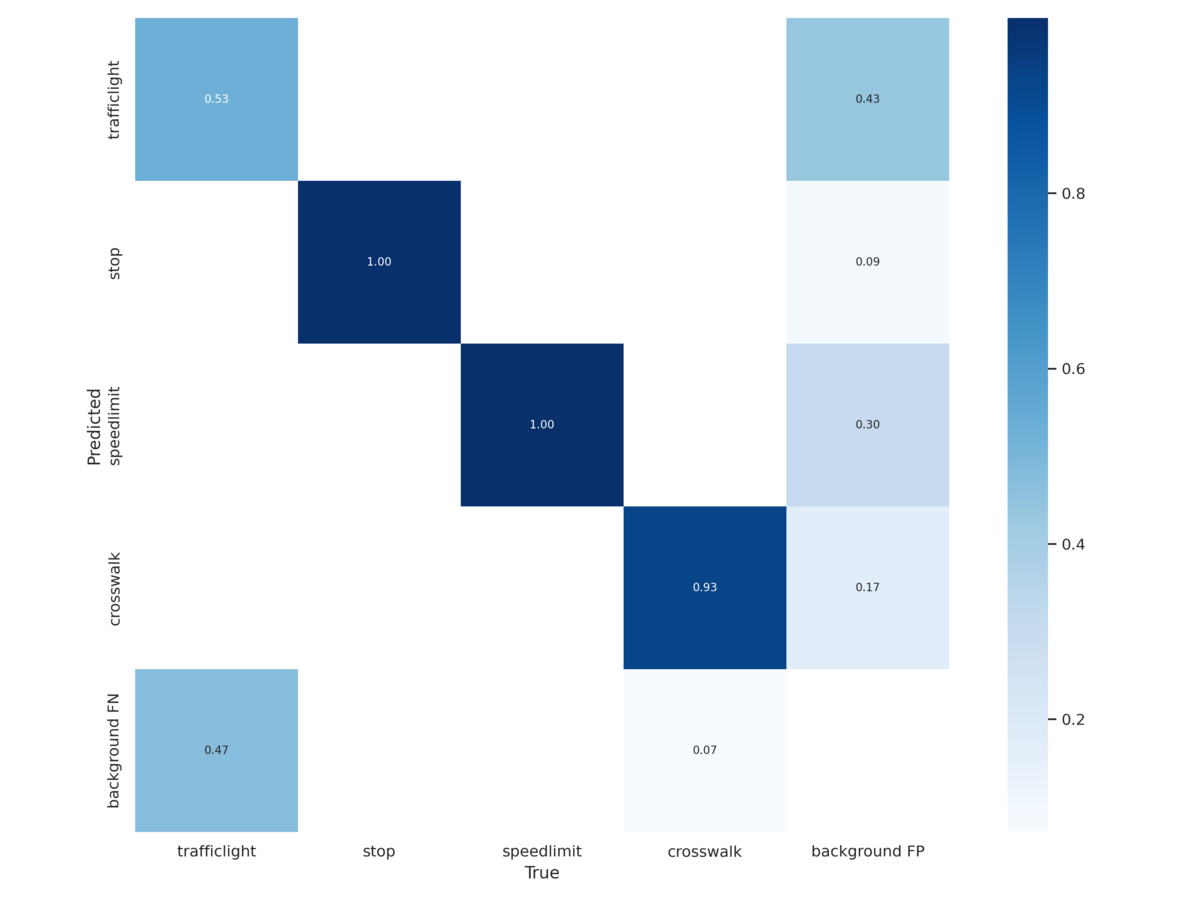
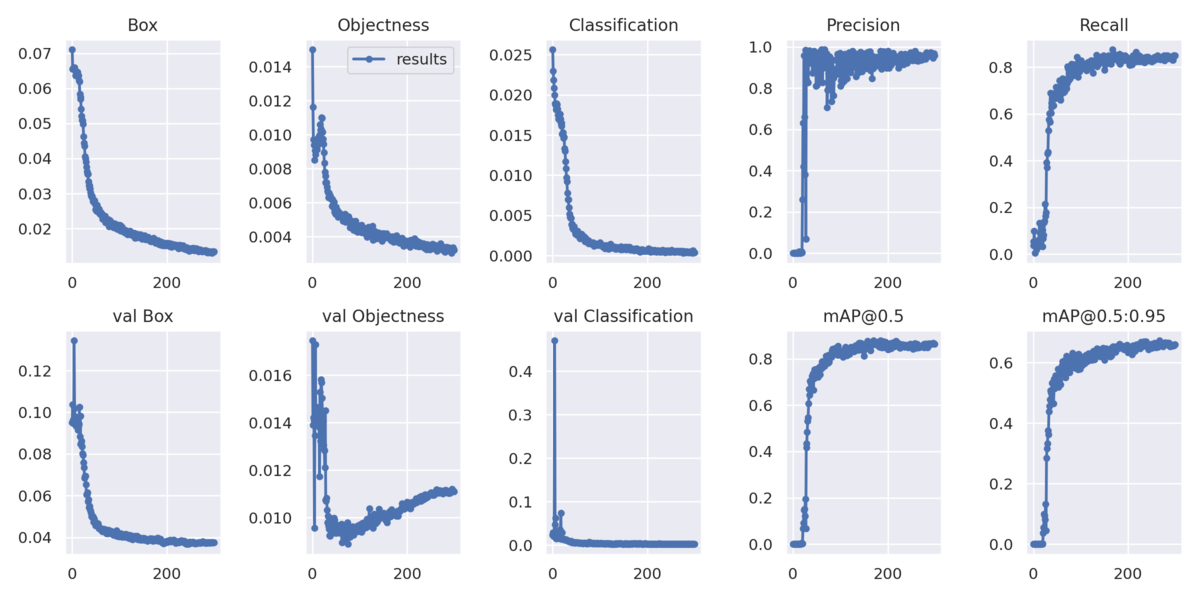
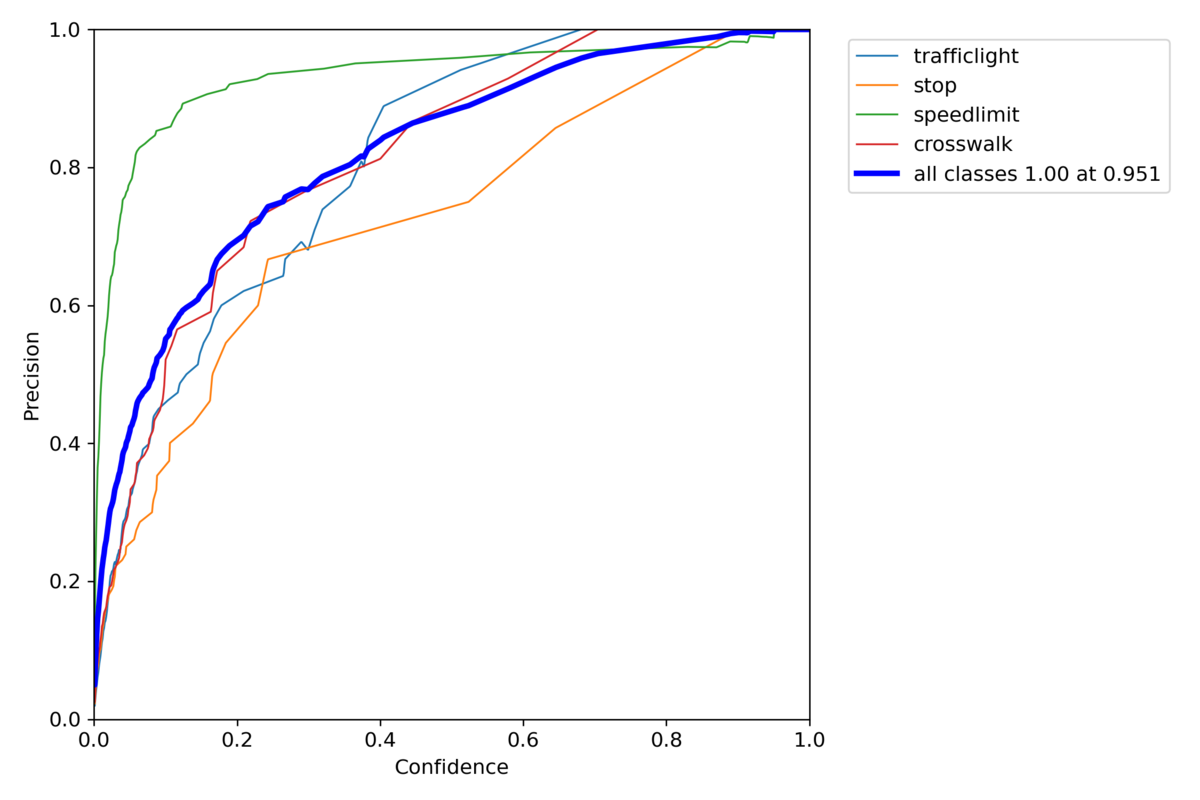
3. 検証結果
普通のYolov7
confusion matrix
loss curve
P_curve
F1 curve
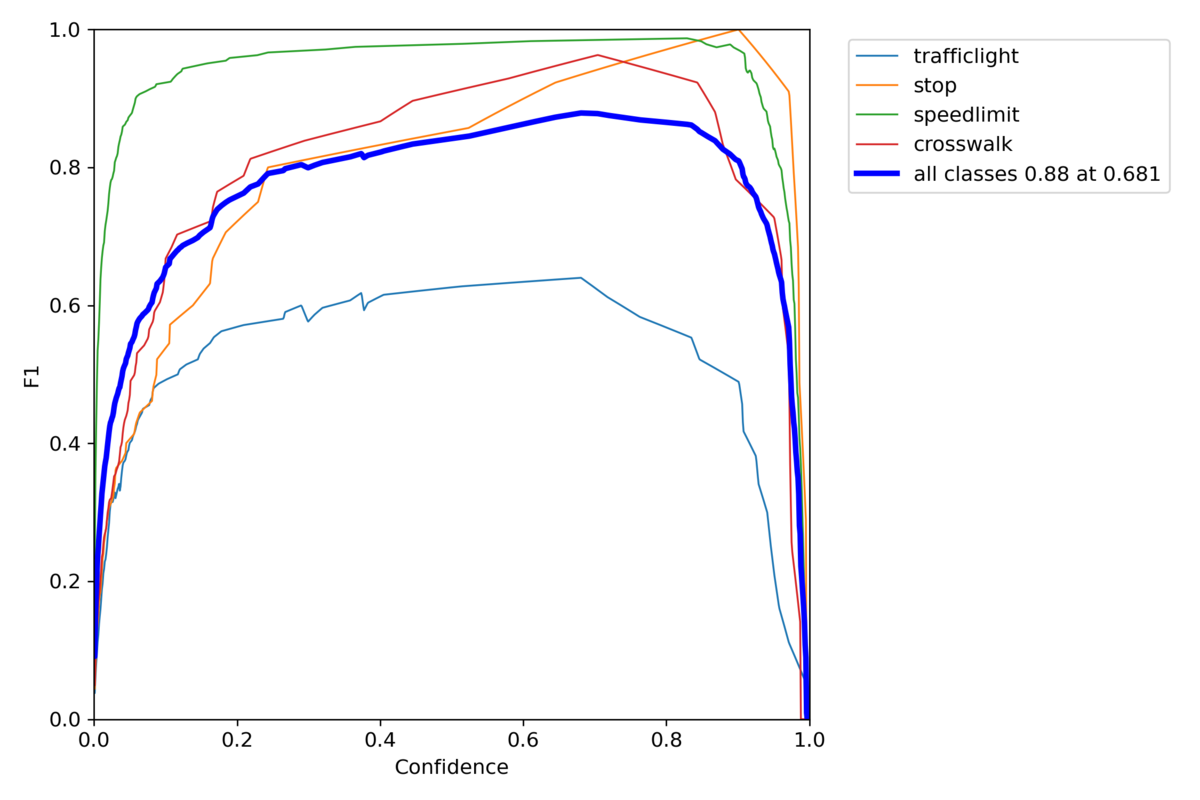
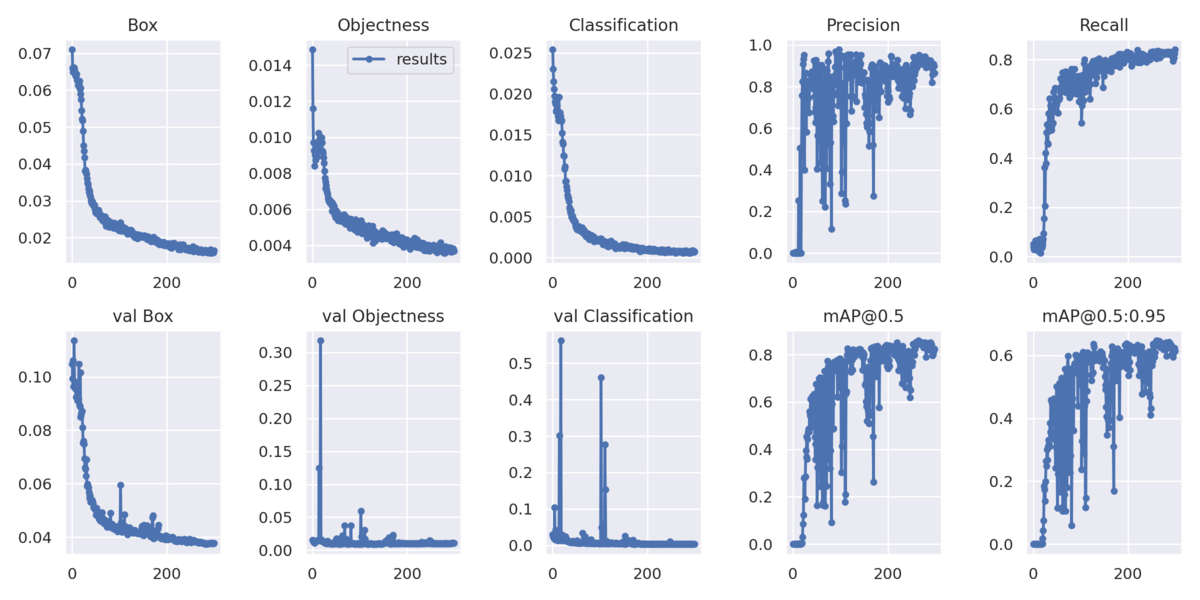
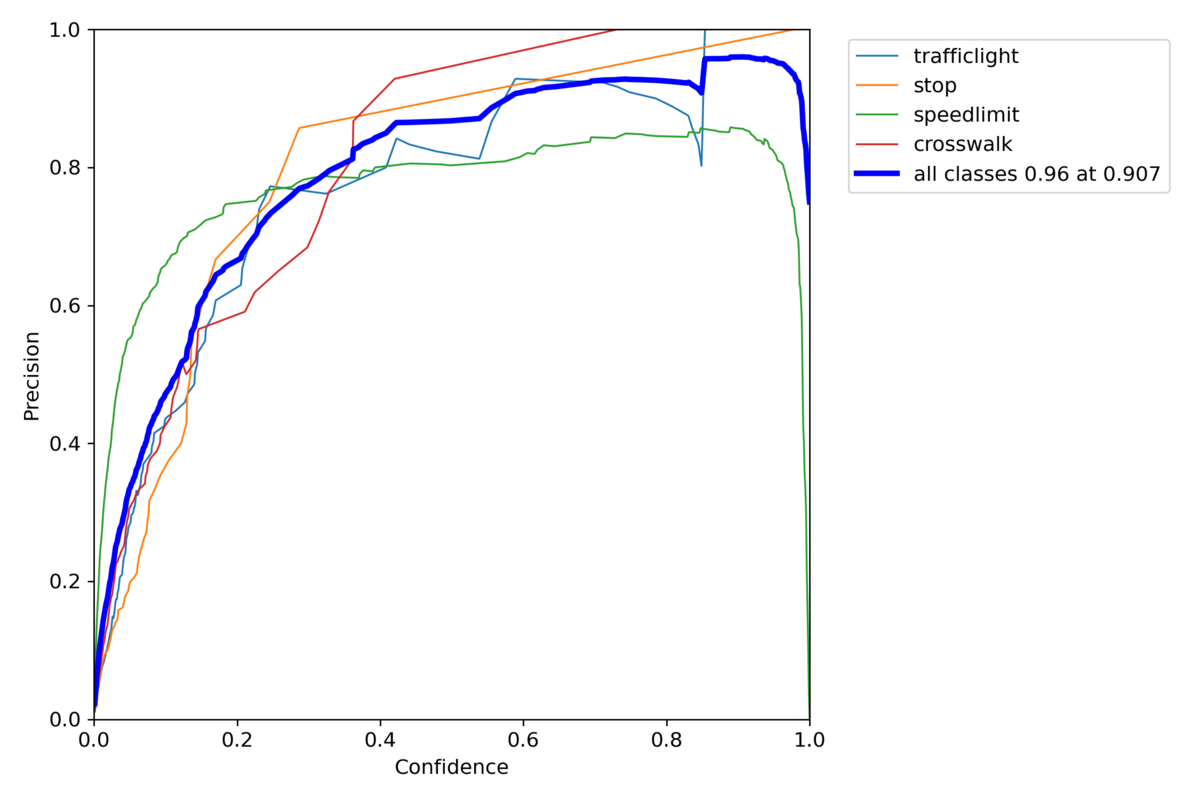
Sinkhornを使ったYolov7
confusion matrix

loss curve
P_curve
F1 curve

うまい具合にいってるけど、全体で的に見るとSinkhornに入れる引数のshapeが3次元の必要性から、使うドメインは限られてくる。
今回はclass lossにしか使ってなかったから、object lossとiou lossに使えばもっと改善する可能性もある。
少なくともlossの改善には悪い影響は与えないんじゃないかと思う。
参照記事
・yolov7・SinkHorn