信号データ(1次元の波形データ)を使った「傷あり/なし」の異常検知モデルを作ったので、役に立ったこと、たたなかったこと、とかを備忘録でまとめてく。
本来のタスクとちょっとルールを変えて、時系列データ自体が異常かどうかの2値分類タスクにした。
目次
1. データについて
2. 1dCNNとLSTMの組み合わせ
3. MultiHead-AttentionとMLP-Blockの活用
4. 結果
5. その他の使えるTips
1. データについて
データの異常・正常のパターンは公開できないけど、少し異常データの方が荒い感じになってる。
異常データが傷がありを示す異常データ。
前処理で異常データの傷の部分を際立つようにした。
1dCNNのインプット形式は、
(batch_size, time_length, chennel)
・前処理前のShape :(batch, 8, 50000~60000)
・前処理後のshape : (batch, 3, 30000)
シンプルにXとY成分を2乗してルート取ったり、位相を強調したり、データの特徴に合わせた前処理をした。
正常データ


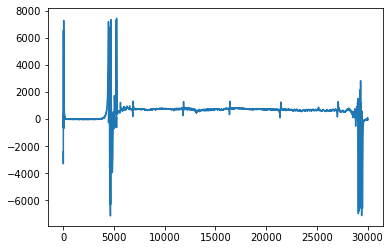
異常データ
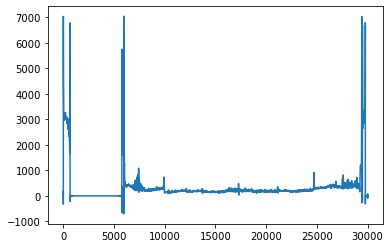
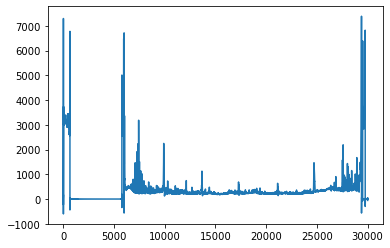
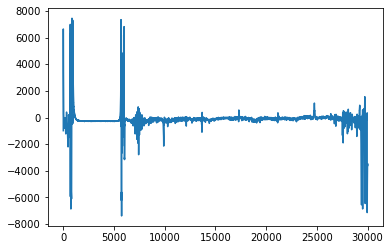
また今回は高周波数でもないし、ノイズは差分で取り除けたので、
は必要ないand 役にたたなかった。
またスペクトル変換してConv2dで処理する方法もあったけど、1データにつき波形が8こ含まれてるため、異常の傷を強調して1dCNNを使った。
バンドパスフィルター
def apply_bandpass(x, lf=1, hf=100, order=16, sr=30000): sos = signal.butter(order, [lf, hf], btype="bandpass", output="sos", fs=sr) normalization = np.sqrt((hf - lf) / (sr / 2)) x = signal.sosfiltfilt(sos, x) / normalization return x
2. 1dCNNとLSTMの組み合わせ
傷を強調するように前処理して、1次元の波形を1dCNNで局所部分の特徴を抽出。そのあとにシーケンスデータとしてそのままLSTMに入れた。
def cnn_embed(self, x): ss = [] xs = x.permute(0, 2, 1) for i in range(self.tstep): xs_ = xs[:, i, :].unsqueeze(1) fts = self.cnn1d(xs_) ss.append(fts) x = torch.cat(ss, dim=1) # Standardization std, mean = torch.std_mean(x, dim=(1,2), unbiased=False, keepdim=True) x = torch.div(x-mean, std) x = self.lstm(x) return x
1dCNNの出力を標準化するのはデータを整える意味で強力。
1dCNNの出力をLSTMに使うのは、
・シーケンス長データの時系列の特徴を抽出できる。
のコンボが強力だと思う。
また1dCNNでpooling層を使うとエイリアシングが起こるらしいけど、今回のデータは周波数変換してないので、pooling層はあっても問題なし。
スペクトル変換して周波数にしてconv1dに入れるなら、pooling層のエイリアシング対策は必要。
3. MultiHead-AttentionとMLP-Blockの活用
Vit(Vision Transformer)を真似して、
・MLP
を使った、Transformerの亜種を作った。
特にnn.LayerNormとLSTMは相性がすごいよかった。
class CNN1d_Transformer(nn.Module): def __init__(self, tstep=4, embed_dim=256, hidden_dim=256): super(CNN1d_Transformer,self).__init__() self.tstep = tstep # Encoder self.cnn1d = CNN1d(embed_dim) self.lstm = LSTMModel(466, hidden_dim) # Decoder self.self_attention = MultiheadSelfAttention(hidden_dim*2, hidden_dim*2, heads=4) self.norm_layer = nn.LayerNorm([768, hidden_dim*2]) self.dropout = nn.Dropout(p=0.2) self.mlp = SelfAttention(hidden_dim*2, hidden_dim*2) def transfomer(self, encout, attention_is=False): ## attention block x = self.norm_layer(encout) #if attention_is: x = self.self_attention(x) x = self.dropout(x) x = x + encout ## mlp block y = self.norm_layer(x) return y
LSTM出力のembed featureをMlutiHead-AttentionとMLPとかのレイヤーに通すことで、いろんな特徴量を得られる。
これらを足し算することで、精度向上や汎化性能、valid loss の改善に一役買ったてくれた。
TransFormerとかMetaFormer
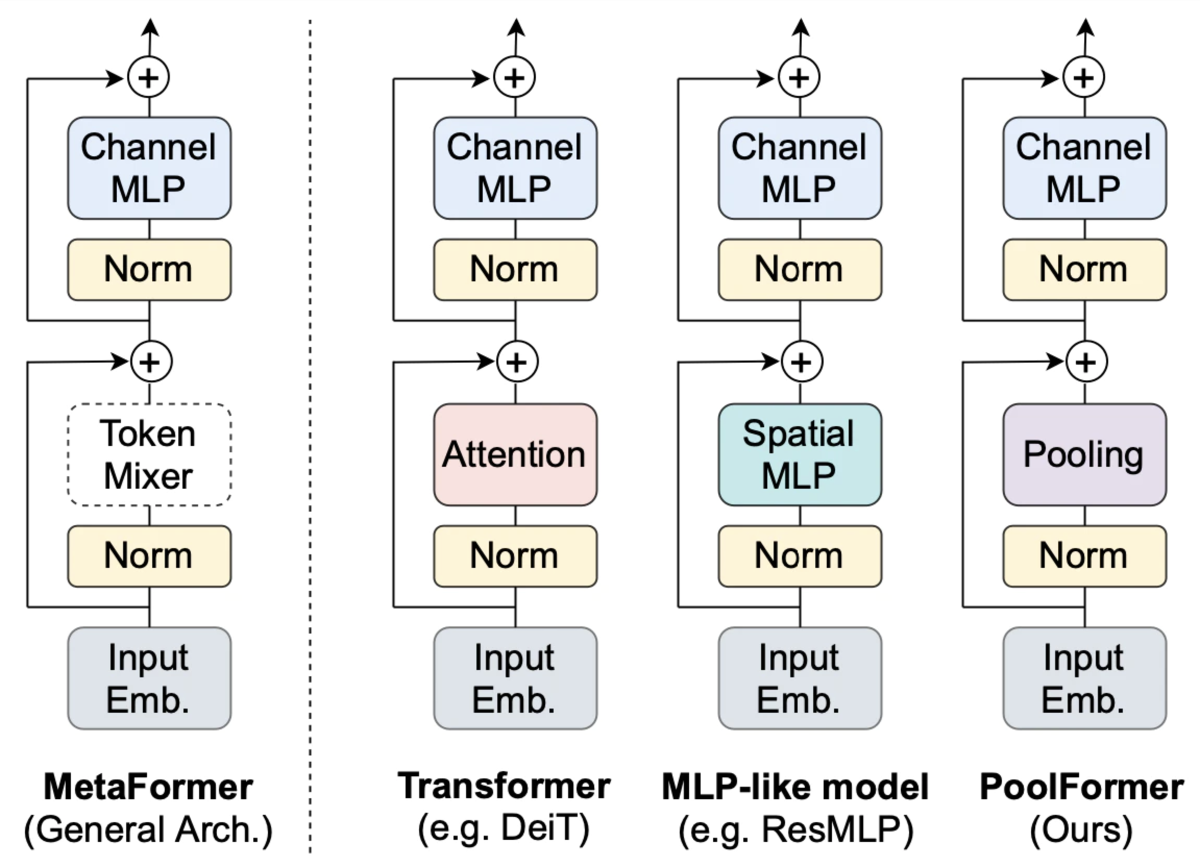
そういえばDeeplabv3+でもASPPとかいうのがあったので、やってることは同じ感じ
ASPP

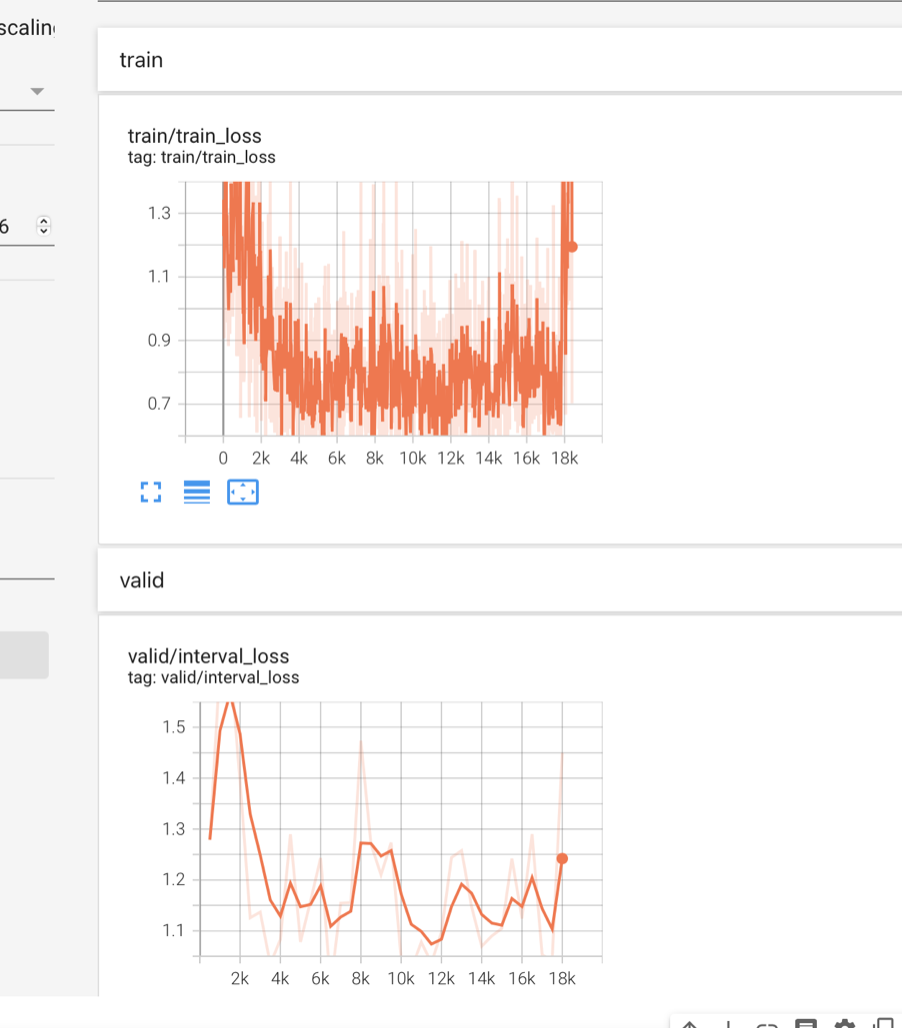
4. 結果
87.5%
loss
5. その他の使えるTips
・1dCNNでフーリエ変換した周波数データはpooling層による、エイリアシングに要注意。
・ニューラルネット中の標準化はデータを整える意味で強力
・augumatationはtimeshiftやノイズ、リサンプルのサイズ変換
また、DTWとか信号処理や音声とかの1次元の手法は画像分野でも使えるので結構面白かった。
やっぱりこんぺの勝ち負けは順位で搾取されるんじゃなくて、どれだけ参加者本人が楽しんで技術アイデアを得るとかなんだよなと常々思った。
参考サイト
https://www.kaggle.com/code/gyozzza/g2net-1dcnn-transformerhttps://github.com/pytorch/vision/blob/main/torchvision/models/vision_transformer.py