今回はVitisPlatfrom構築に必要な「Vitis、Petalinux、その他関連ツール」のインストール。
「Ultra96の開発環境(Vitis2019.2版)」をメインに参考にした。
Vitisプラットフォーム(vitis IDE)はVivado起動後に、「Ultra96用Vitisプラットフォームの作り方(BASE編)」を参考に次記事でやる予定。
前回作った仮想環境用ネットワークを少し改良して、外付けHDDの中にVirtualBoxをいれて仮想環境を作った。
そこにUbuntu Linux 18.04.2 LTS (64 ビット)を入れて、vitisとPetaLinuxとかをインストールして、Vivadoを起動するまで。
VirtualBoxで作ったubuntuの仮想環境のストレージ容量は、VitisとPetaLinuxを入れるために500GBくらいのを作った。
改良ネットワーク図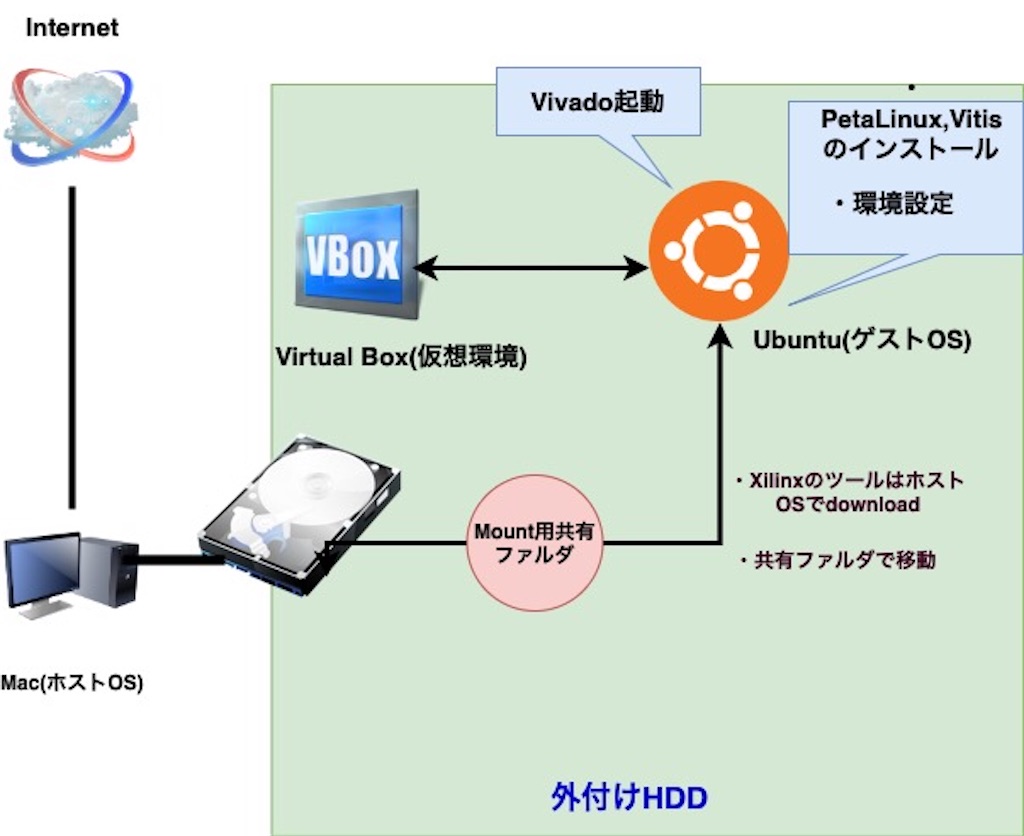
目次
1.ゲストOS側でライブラリの準備
2.Vitisのインストール
3.その他必要なツールのインストール
4.ゲストOS側からVivadoの起動
1.ゲストOS側で必要なライブラリの準備
Vitisプラットフォーム構築に必要なライブラリをゲストOS側でインストール。
$ sudo dpkg --add-architecture i386 && sudo apt update && sudo apt install apt-utils libc6:i386 libncurses5:i386 libstdc++6:i386 g++-multilib libgtk2.0-0:i386 dpkg-dev:i386 libxtst6:i386 default-jre unzip net-tools libtext-csv-perl libcanberra-gtk-module libcanberra-gtk3-module lsb-core opencl-headers ocl-icd-opencl-dev ocl-icd-libopencl1 wget -y && sudo ln -s /usr/bin/make /usr/bin/gmake $ sudo apt install tofrodos iproute2 gawk make net-tools locales cpio libncurses5-dev libssl-dev flex bison libselinux1 gnupg wget diffstat chrpath socat xterm autoconf libtool tar unzip texinfo zlib1g-dev gcc-multilib build-essential libsdl1.2-dev libglib2.0-dev screen pax gzip xvfb tftpd tftp libtool-bin default-jre -y lsb-release zlib1g:i386 git python-dev $ sudo apt-get install -y binutils ncurses-dev u-boot-tools file iproute2 tftpd-hpa diffstat x11-apps less etckeeper jed $ sudo locale-gen en_US.UTF-8 # 有効なインストール可能なパッケージの一覧を更新(update) & 有効なパッケージ一覧を元にインストール済みパッケージの更新 (upgrade) $ sudo apt-get update && sudo apt-get upgrade $ sudo apt autoremove
参考記事:xilinx2017.2_dep.sh(github)
2.Vitisのインストール
1.Vitisのダウンロード
Vitisはこのページからダウンロード。
ダウンロードするものは、
・ザイリンクス統合インストーラー 2019.2: Linux 用自己解凍型ウェブインストーラー(BIN - 115.4MB)
2.ウェブインストーラーの実行
ホストOS側でダウンロード後、ゲストOS側(ubuntu側)に移動して、ウェブインストーラーを実行。
# ゲストOS側で実行 $ sudo chmod 777 Xilinx_Unified_2019.2_1106_2127_Lin64.bin $ ./Xilinx_Unified_2019.2_1106_2127_Lin64.bin
注意事項を聞かれるのでOKした後に、インストール開始画面になる。
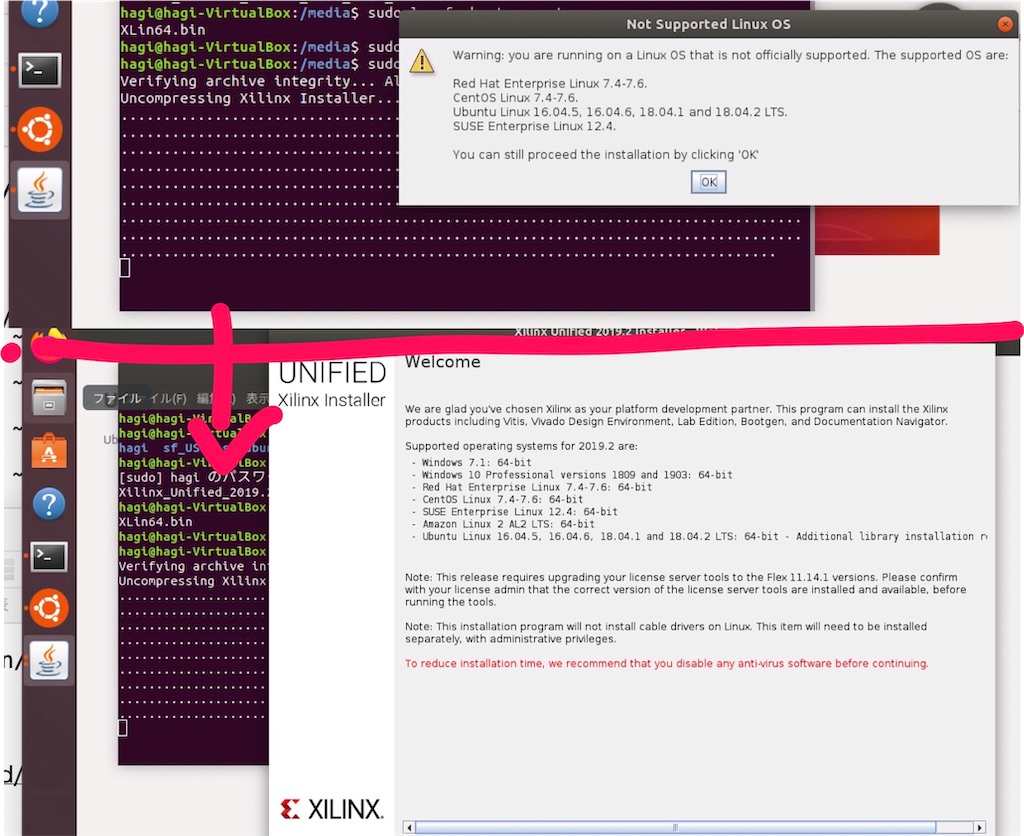
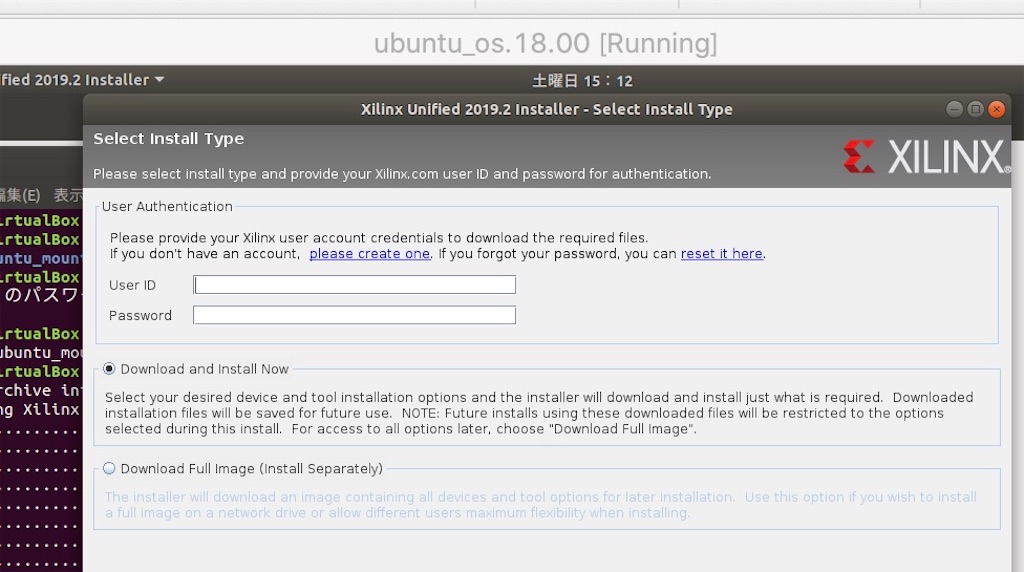
途中でXlinxのアカウント入力が必要。
インストール対象に「Vitis」を選択をした後、保存先を聞かれる。
ホストOS内のVivadoフォルダのパス「/media/[host-name]/Vivado」を指定。500GBもあるので十分足りる。
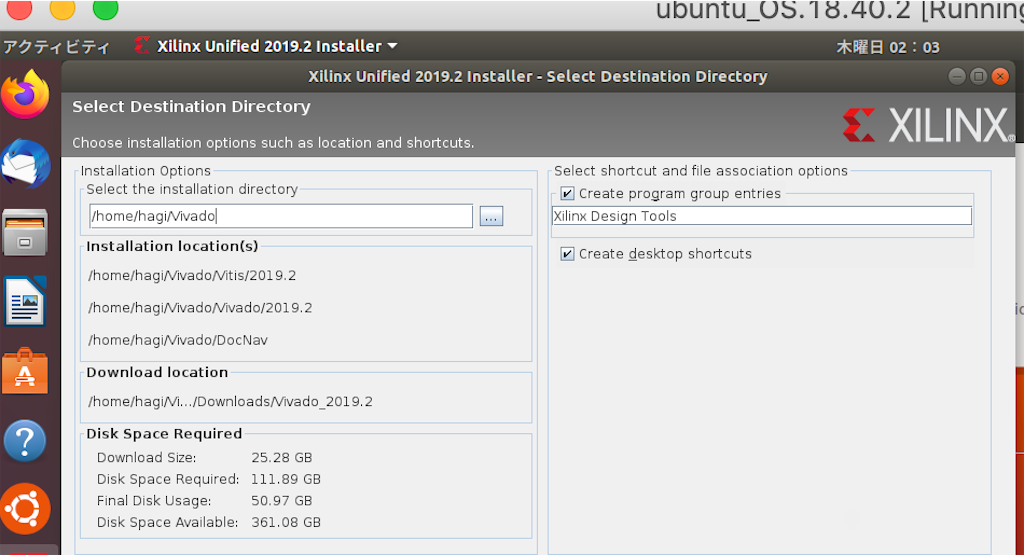
インストール開始画面

インストール中
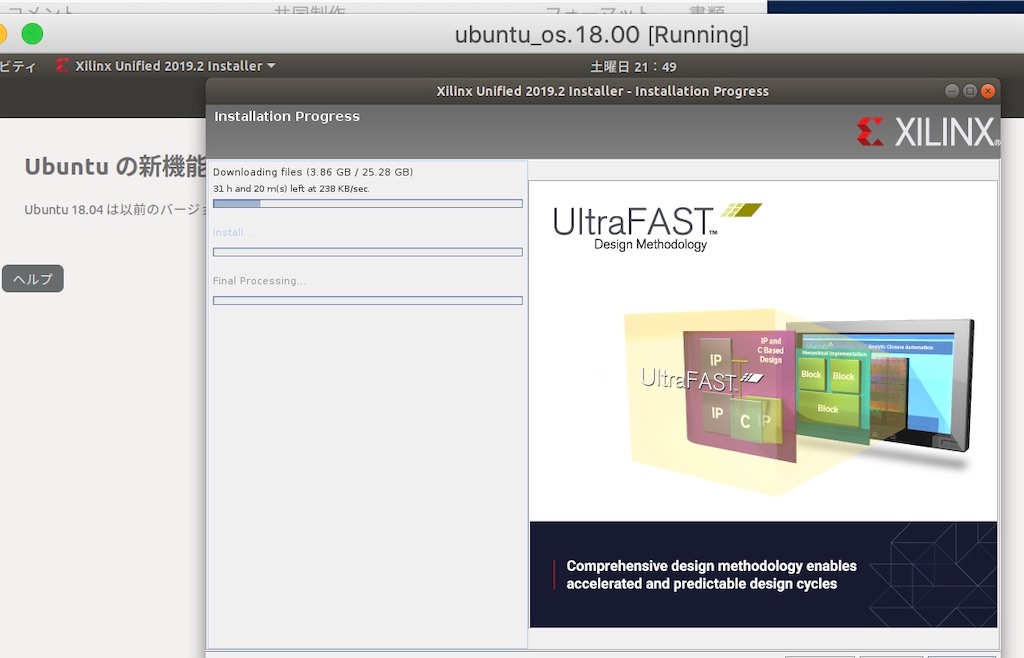
インストール完了
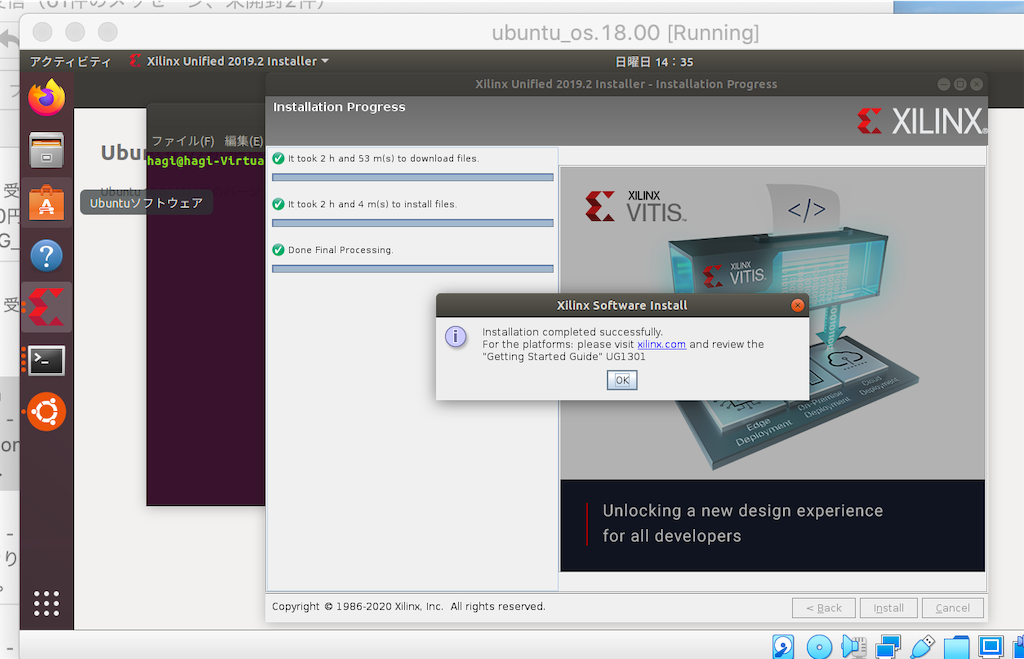
インストール完了までは気長に待つだけ。
licenseの取得
次にvivadoで必要になるxilinxのlicenseの取得。
ページからvivado HLSのライセンスを取得。(これをしないと高位合成のときSynthesis errorになる)。
Obtain Licenseを選び、ラジオボックスを上から2番目(Get Vivado or IP〜)に合わせ、Connect Nowを起動。

Xilinxのサインインを済ませ、Product Licensingのページに移動し、したの画面の基本licenseに全部チェックして取得。
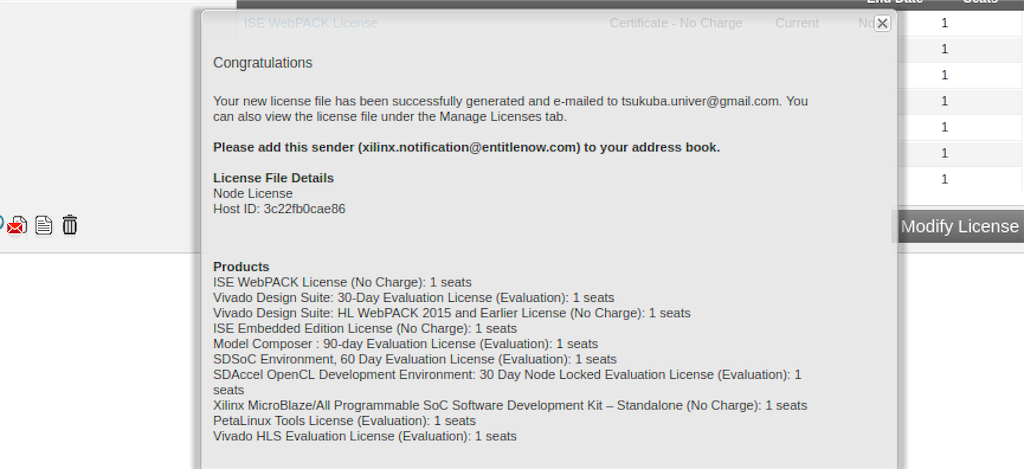
するとXilinxからメールが届いて、「Xilinx.lic」が添えつけられているので、適当な場所に配置
# Xilinx.licをVivadoファルダに移動 $ mv /media/[マウントフォルダ]/Xilinx.lic Vivado/ $ sudo chmod 777 Xilinx.lic
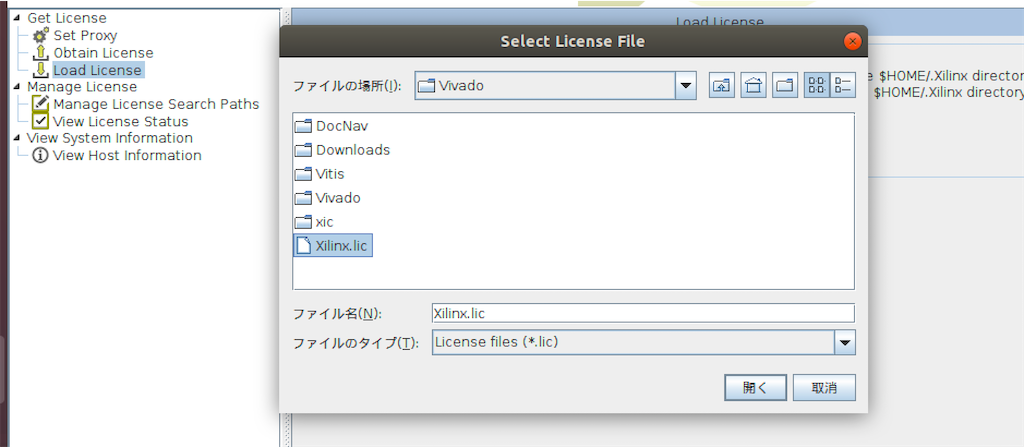
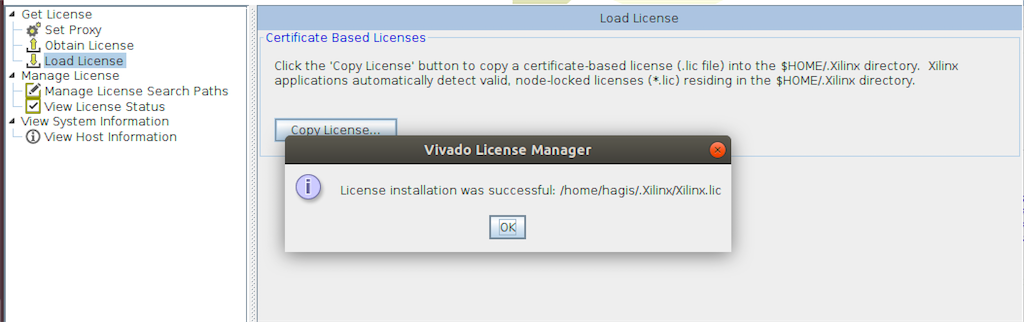
あとはLicence ManagerのLoad Licenseを起動し、Copy Licenseをクリック。

Xilinx.licを選べば完了。
3.その他必要なツールのインストール
・Petalinux
1.Petalinuxのインストール
このサイトから下のをdownload。
・PetaLinux 2019.2 インストーラ(TAR/GZIP - 7.92GB)
ちなみにrootユーザーではインストーラの実行ができない。
ホストOS側でダウンロードしたものを、マウント共有フォルダでゲストOS内移動して、実行した。
# check user name $ whoami # user $ export USER=user $ sudo mkdir -p /opt/petalinux/ $ sudo chmod -R 777 /opt/petalinux/ $ sudo chown $USER:$USER /opt/petalinux # /home/userのところでinstallの実行 $ sudo chmod 777 petalinux-v2019.2-final-installer.run $ ./petalinux-v2019.2-final-installer.run /opt/petalinux >>>>> INFO: Checking installation environment requirements... INFO: Checking free disk space INFO: Checking installed tools INFO: Checking installed development libraries INFO: Checking network and other services INFO: Checking installer checksum... INFO: Extracting PetaLinux installer... LICENSE AGREEMENTS 〜 INFO: Installing PetaLinux... ********************************************* WARNING: PetaLinux installation directory: /opt/petalinux/. is not empty! ********************************************* Please input "y" to continue to install PetaLinux in that directory?[n]y INFO: Checking PetaLinux installer integrity... INFO: Installing PetaLinux SDK to "/opt/petalinux/." INFO: Installing aarch64 Yocto SDK to "/opt/petalinux/./components/yocto/source/aarch64"... INFO: Installing arm Yocto SDK to "/opt/petalinux/./components/yocto/source/arm"... INFO: Installing microblaze_full Yocto SDK to "/opt/petalinux/./components/yocto/source/microblaze_full"... INFO: Installing microblaze_lite Yocto SDK to "/opt/petalinux/./components/yocto/source/microblaze_lite"... INFO: PetaLinux SDK has been installed to /opt/petalinux/.
インストール後、PetaLinuxツール(components, doc, etc, tools, settings.csh, settings.sh)の確認。
$ ls
components doc etc settings.csh settings.sh tools
・XRTライブラリ(ザイリンクスランタイム)
XRTはライブラリなので、実行してもフォルダは出現しない。
# xilinxツール用ディレクトリ作成(sshでログインして実行) $ mkdir xilinx_drivers && cd xilinx_drivers $ wget https://www.xilinx.com/bin/public/openDownload?filename=xrt_201920.2.3.1301_18.04-xrt.deb -O xrt_201920.2.3.1301_18.04-xrt.deb # 実行 $ sudo apt install ./xrt_201920.2.3.1301_18.04-xrt.deb -y >>>> DKMS: install completed. Finished DKMS common.postinst Loading new XRT Linux kernel modules Installing MSD / MPD daemons 〜 Collecting pyopencl Downloading https://files.pythonhosted.org/packages/a1/b5/c32aaa78e76fefcb294f4ad6aba7ec592d59b72356ca95bcc4abfb98af3e/pyopencl-2020.2.tar.gz (351kB) 100% |████████████████████████████████| 358kB 2.6MB/s Complete output from command python setup.py egg_info: 〜 create mode 100644 OpenCL/vendors/xilinx.icd create mode 100644 bash_completion.d/dkms 〜 create mode 100644 systemd/system/mpd.service create mode 100644 systemd/system/msd.service create mode 100644 udev/rules.d/10-xclmgmt.rules create mode 100644 udev/rules.d/10-xocl.rules
・ボードファイル
# sshでログインして実行 $ cd xilinx_drivers # wget https://github.com/Avnet/bdf/archive/master.zip && unzip master.zip # new board copy $ unzip -o vivado-boards-master.zip $ sudo cp -rf vivado-boards-master/new/board_files/* /home/user/Vivado/2019.2/data/boards/board_files/ $ sudo rm -rf vivado-boards-master # copy usual board $ unzip -o bdf-master.zip $ sudo cp -rf bdf-master/* /home/user/Vivado/2019.2/data/boards/board_files/ $ sudo rm -rf bdf-master
・ケーブルドライバー
$ cd Vivado/2019.2/data/xicom/cable_drivers/lin64/install_script/install_drivers $ sudo ./install_drivers >>>>> INFO: Installing cable drivers. INFO: Script name = ./install_drivers INFO: HostName = hagi-VirtualBox INFO: Current working dir = /home/[host-name]/Vivado/Vivado/2019.2/data/xicom/cable_drivers/lin64/install_script/install_drivers INFO: Kernel version = 5.3.0-42-generic. INFO: Arch = x86_64. Successfully installed Digilent Cable Drivers --File /etc/udev/rules.d/52-xilinx-ftdi-usb.rules does not exist. --File version of /etc/udev/rules.d/52-xilinx-ftdi-usb.rules = 0000. --Updating rules file. --File /etc/udev/rules.d/52-xilinx-pcusb.rules does not exist. --File version of /etc/udev/rules.d/52-xilinx-pcusb.rules = 0000. --Updating rules file. INFO: Digilent Return code = 0 INFO: Xilinx Return code = 0 INFO: Xilinx FTDI Return code = 0 INFO: Return code = 0 INFO: Driver installation successful. CRITICAL WARNING: Cable(s) on the system must be unplugged then plugged back in order for the driver scripts to update the cables.
・環境変数の設定
# LD_LIBRARY_PATH の設定 $ export GID=`id -g` $ sudo chown ${UID}:${GID} /home/$USER/.bashrc # ゲストOSの環境変数の設定 $ sudo echo "source /home/〜/Vivado/2019.2/settings64.sh" >> ~/.bashrc $ sudo echo "source /home/〜/Vitis/2019.2/settings64.sh" >> ~/.bashrc $ sudo echo "source /opt/xilinx/xrt/setup.sh " >> ~/.bashrc $ sudo echo "source /opt/petalinux/settings.sh " >> ~/.bashrc
あとは念のためGUIで再起動(CUI:$sudo reboot)
4.ゲストOS側からVivadoの起動
# Vivadoコマンドを起動 $ /home/〜/Vivado/2019.2/bin/vivado
起動できた。
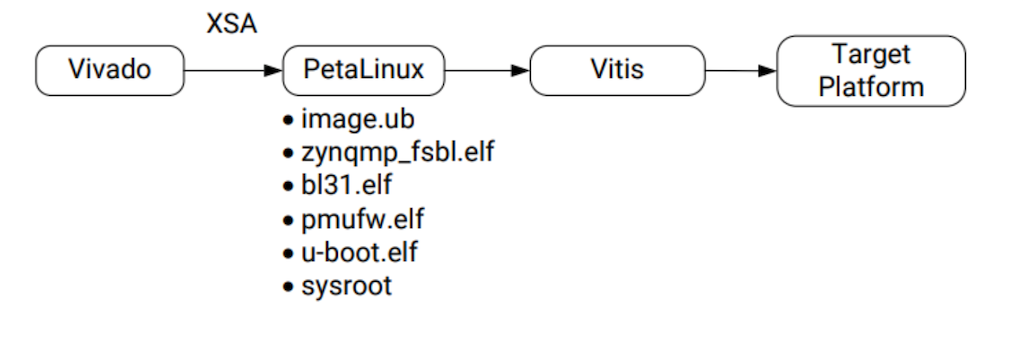
後は以下の図の流れでVitisPlatformを構築していく。
参考サイト
・[https://qiita.com/georgioush/items/1e19ecd9a9ef8be886d7:title=Vivado License Error [17-345]]
・Vitis 2019.2 をインストールした(FPGAの部屋)















































