Jetson Nanoで以前USBカメラを接続した。
trafalbad.hatenadiary.jp
今回VNC接続した身軽な状態のjetson nanoで撮影したカメラ画像を、遠隔でホストPCのGoogle chrome (Safari)で表示してみた。
その備忘録
目次
1. Jetson Nanoでブラウザに表示するための準備
2. 遠隔のホストPCのブラウザにカメラ画像を表示
1.Jetson Nanoでブラウザに表示するための準備
cd ~/catkin_ws/src
catkin_create_pkg video_stream roscpp std_msgs rosilb image_transport cv_bridge
cd ~/catkin_ws
catkin_make
source ~/.bashrc
以下のcppスクリプト書き換え
video_stream.cpp
#include <ros_video_stream/ros_video_stream.h>
#include <sys/ioctl.h>
#include <errno.h>
#include <signal.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <syslog.h>
#include <netdb.h>
#include <errno.h>
#include <opencv2/opencv.hpp>
#include <boost/thread.hpp>
#include <boost/bind.hpp>
#define CV_IMWRITE_JPEG_QUALITY 10
template<typename T>
inline T ABS(T a)
{
return (a < 0 ? -a : a);
}
template<typename T>
inline T min(T a, T b)
{
return (a < b ? a : b);
}
template<typename T>
inline T max(T a, T b)
{
return (a > b ? a : b);
}
template<typename T>
inline T LENGTH_OF(T x)
{
return (sizeof(x) / sizeof(x[0]));
}
namespace mjpeg_server
{
MJPEGServer::MJPEGServer(ros::NodeHandle& node) :
node_(node), image_transport_(node), stop_requested_(false), www_folder_(NULL)
{
ros::NodeHandle private_nh("~");
private_nh.param("port", port_, 8080);
header = "Connection: close\r\nServer: mjpeg_server\r\n"
"Cache-Control: no-cache, no-store, must-revalidate, pre-check=0, post-check=0, max-age=0\r\n"
"Pragma: no-cache\r\n";
sd_len = 0;
}
MJPEGServer::~MJPEGServer()
{
cleanUp();
}
void MJPEGServer::imageCallback(const sensor_msgs::ImageConstPtr& msg, const std::string& topic)
{
ImageBuffer* image_buffer = getImageBuffer(topic);
boost::unique_lock<boost::mutex> lock(image_buffer->mutex_);
image_buffer->msg = *msg;
image_buffer->condition_.notify_all();
}
void MJPEGServer::splitString(const std::string& str, std::vector<std::string>& tokens, const std::string& delimiter)
{
std::string::size_type lastPos = str.find_first_not_of(delimiter, 0);
std::string::size_type pos = str.find_first_of(delimiter, lastPos);
while (std::string::npos != pos || std::string::npos != lastPos)
{
tokens.push_back(str.substr(lastPos, pos - lastPos));
lastPos = str.find_first_not_of(delimiter, pos);
pos = str.find_first_of(delimiter, lastPos);
}
}
int MJPEGServer::stringToInt(const std::string& str, const int default_value)
{
int value;
int res;
if (str.length() == 0)
return default_value;
res = sscanf(str.c_str(), "%i", &value);
if (res == 1)
return value;
return default_value;
}
void MJPEGServer::initIOBuffer(iobuffer *iobuf)
{
memset(iobuf->buffer, 0, sizeof(iobuf->buffer));
iobuf->level = 0;
}
void MJPEGServer::initRequest(request *req)
{
req->type = A_UNKNOWN;
req->type = A_UNKNOWN;
req->parameter = NULL;
req->client = NULL;
req->credentials = NULL;
}
void MJPEGServer::freeRequest(request *req)
{
if (req->parameter != NULL)
free(req->parameter);
if (req->client != NULL)
free(req->client);
if (req->credentials != NULL)
free(req->credentials);
}
int MJPEGServer::readWithTimeout(int fd, iobuffer *iobuf, char *buffer, size_t len, int timeout)
{
size_t copied = 0;
int rc, i;
fd_set fds;
struct timeval tv;
memset(buffer, 0, len);
while ((copied < len))
{
i = min((size_t)iobuf->level, len - copied);
memcpy(buffer + copied, iobuf->buffer + IO_BUFFER - iobuf->level, i);
iobuf->level -= i;
copied += i;
if (copied >= len)
return copied;
tv.tv_sec = timeout;
tv.tv_usec = 0;
FD_ZERO(&fds);
FD_SET(fd, &fds);
if ((rc = select(fd + 1, &fds, NULL, NULL, &tv)) <= 0)
{
if (rc < 0)
exit(EXIT_FAILURE);
return copied;
}
initIOBuffer(iobuf);
if ((iobuf->level = read(fd, &iobuf->buffer, IO_BUFFER)) <= 0)
{
return -1;
}
memmove(iobuf->buffer + (IO_BUFFER - iobuf->level), iobuf->buffer, iobuf->level);
}
return 0;
}
int MJPEGServer::readLineWithTimeout(int fd, iobuffer *iobuf, char *buffer, size_t len, int timeout)
{
char c = '\0', *out = buffer;
unsigned int i;
memset(buffer, 0, len);
for (i = 0; i < len && c != '\n'; i++)
{
if (readWithTimeout(fd, iobuf, &c, 1, timeout) <= 0)
{
return -1;
}
*out++ = c;
}
return i;
}
void MJPEGServer::decodeBase64(char *data)
{
union
{
int i;
char c[4];
} buffer;
char* ptr = data;
unsigned int size = strlen(data);
char* temp = new char[size];
char* tempptr = temp;
char t;
for (buffer.i = 0, t = *ptr; ptr; ptr++)
{
if (t >= 'A' && t <= 'Z')
t = t - 'A';
else if (t >= 'a' && t <= 'z')
t = t - 'a' + 26;
else if (t >= '0' && t <= '9')
t = t - '0' + 52;
else if (t == '+')
t = 62;
else if (t == '/')
t = 63;
else
continue;
buffer.i = (buffer.i << 6) | t;
if ((ptr - data + 1) % 4)
{
*tempptr++ = buffer.c[2];
*tempptr++ = buffer.c[1];
*tempptr++ = buffer.c[0];
buffer.i = 0;
}
}
*tempptr = '\0';
strcpy(data, temp);
delete temp;
}
int MJPEGServer::hexCharToInt(char in)
{
if (in >= '0' && in <= '9')
return in - '0';
if (in >= 'a' && in <= 'f')
return (in - 'a') + 10;
if (in >= 'A' && in <= 'F')
return (in - 'A') + 10;
return -1;
}
int MJPEGServer::unescape(char *string)
{
char *source = string, *destination = string;
int src, dst, length = strlen(string), rc;
for (dst = 0, src = 0; src < length; src++)
{
if (source[src] != '%')
{
destination[dst] = source[src];
dst++;
continue;
}
if (src + 2 > length)
{
return -1;
break;
}
if ((rc = hexCharToInt(source[src + 1])) == -1)
return -1;
destination[dst] = rc * 16;
if ((rc = hexCharToInt(source[src + 2])) == -1)
return -1;
destination[dst] += rc;
dst++;
src += 2;
}
destination[dst] = '\0';
return 0;
}
void MJPEGServer::sendError(int fd, int which, const char *message)
{
char buffer[BUFFER_SIZE] = {0};
if (which == 401)
{
sprintf(buffer, "HTTP/1.0 401 Unauthorized\r\n"
"Content-type: text/plain\r\n"
"%s"
"WWW-Authenticate: Basic realm=\"MJPG-Streamer\"\r\n"
"\r\n"
"401: Not Authenticated!\r\n"
"%s",
header.c_str(), message);
}
else if (which == 404)
{
sprintf(buffer, "HTTP/1.0 404 Not Found\r\n"
"Content-type: text/plain\r\n"
"%s"
"\r\n"
"404: Not Found!\r\n"
"%s",
header.c_str(), message);
}
else if (which == 500)
{
sprintf(buffer, "HTTP/1.0 500 Internal Server Error\r\n"
"Content-type: text/plain\r\n"
"%s"
"\r\n"
"500: Internal Server Error!\r\n"
"%s",
header.c_str(), message);
}
else if (which == 400)
{
sprintf(buffer, "HTTP/1.0 400 Bad Request\r\n"
"Content-type: text/plain\r\n"
"%s"
"\r\n"
"400: Not Found!\r\n"
"%s",
header.c_str(), message);
}
else
{
sprintf(buffer, "HTTP/1.0 501 Not Implemented\r\n"
"Content-type: text/plain\r\n"
"%s"
"\r\n"
"501: Not Implemented!\r\n"
"%s",
header.c_str(), message);
}
if (write(fd, buffer, strlen(buffer)) < 0)
{
ROS_DEBUG("write failed, done anyway");
}
}
void MJPEGServer::decodeParameter(const std::string& parameter, ParameterMap& parameter_map)
{
std::vector<std::string> parameter_value_pairs;
splitString(parameter, parameter_value_pairs, "?&");
for (size_t i = 0; i < parameter_value_pairs.size(); i++)
{
std::vector<std::string> parameter_value;
splitString(parameter_value_pairs[i], parameter_value, "=");
if (parameter_value.size() == 1)
{
parameter_map.insert(std::make_pair(parameter_value[0], std::string("")));
}
else if (parameter_value.size() == 2)
{
parameter_map.insert(std::make_pair(parameter_value[0], parameter_value[1]));
}
}
}
ImageBuffer* MJPEGServer::getImageBuffer(const std::string& topic)
{
boost::unique_lock<boost::mutex> lock(image_maps_mutex_);
ImageSubscriberMap::iterator it = image_subscribers_.find(topic);
if (it == image_subscribers_.end())
{
image_subscribers_[topic] = image_transport_.subscribe(topic, 1,
boost::bind(&MJPEGServer::imageCallback, this, _1, topic));
image_buffers_[topic] = new ImageBuffer();
ROS_INFO("Subscribing to topic %s", topic.c_str());
}
ImageBuffer* image_buffer = image_buffers_[topic];
return image_buffer;
}
void MJPEGServer::invertImage(const cv::Mat& input, cv::Mat& output)
{
cv::Mat_<cv::Vec3b>& input_img = (cv::Mat_<cv::Vec3b>&)input;
cv::Mat_<cv::Vec3b>& output_img = (cv::Mat_<cv::Vec3b>&)output;
cv::Size size = input.size();
for (int j = 0; j < size.height; ++j)
for (int i = 0; i < size.width; ++i)
{
output_img(size.height - j - 1, size.width - i - 1) = input_img(j, i);
}
return;
}
void MJPEGServer::sendStream(int fd, const char *parameter)
{
unsigned char *frame = NULL, *tmp = NULL;
int frame_size = 0, max_frame_size = 0;
int tenk = 10 * 1024;
char buffer[BUFFER_SIZE] = {0};
double timestamp;
cv_bridge::CvImage image_bridge;
ROS_DEBUG("Decoding parameter");
std::string params = parameter;
ParameterMap parameter_map;
decodeParameter(params, parameter_map);
ParameterMap::iterator itp = parameter_map.find("topic");
if (itp == parameter_map.end())
return;
std::string topic = itp->second;
increaseSubscriberCount(topic);
ImageBuffer* image_buffer = getImageBuffer(topic);
ROS_DEBUG("preparing header");
sprintf(buffer, "HTTP/1.0 200 OK\r\n"
"%s"
"Content-Type: multipart/x-mixed-replace;boundary=boundarydonotcross \r\n"
"\r\n"
"--boundarydonotcross \r\n",
header.c_str());
if (write(fd, buffer, strlen(buffer)) < 0)
{
free(frame);
return;
}
ROS_DEBUG("Headers send, sending stream now");
while (!stop_requested_)
{
{
boost::unique_lock<boost::mutex> lock(image_buffer->mutex_);
image_buffer->condition_.wait(lock);
cv_bridge::CvImagePtr cv_msg;
try
{
if (cv_msg = cv_bridge::toCvCopy(image_buffer->msg, "bgr8"))
{
;
}
else
{
ROS_ERROR("Unable to convert %s image to bgr8", image_buffer->msg.encoding.c_str());
return;
}
}
catch (...)
{
ROS_ERROR("Unable to convert %s image to ipl format", image_buffer->msg.encoding.c_str());
return;
}
cv::Mat img = cv_msg->image;
std::vector<uchar> encoded_buffer;
std::vector<int> encode_params;
if (parameter_map.find("invert") != parameter_map.end())
{
cv::Mat cloned_image = img.clone();
invertImage(cloned_image, img);
}
int quality = 95;
if (parameter_map.find("quality") != parameter_map.end())
{
quality = stringToInt(parameter_map["quality"]);
}
encode_params.push_back(CV_IMWRITE_JPEG_QUALITY);
encode_params.push_back(quality);
if (parameter_map.find("width") != parameter_map.end() && parameter_map.find("height") != parameter_map.end())
{
int width = stringToInt(parameter_map["width"]);
int height = stringToInt(parameter_map["height"]);
if (width > 0 && height > 0)
{
cv::Mat img_resized;
cv::Size new_size(width, height);
cv::resize(img, img_resized, new_size);
cv::imencode(".jpeg", img_resized, encoded_buffer, encode_params);
}
else
{
cv::imencode(".jpeg", img, encoded_buffer, encode_params);
}
}
else
{
cv::imencode(".jpeg", img, encoded_buffer, encode_params);
}
frame_size = encoded_buffer.size();
if (frame_size > max_frame_size)
{
ROS_DEBUG("increasing frame buffer size to %d", frame_size);
max_frame_size = frame_size + tenk;
if ((tmp = (unsigned char*)realloc(frame, max_frame_size)) == NULL)
{
free(frame);
sendError(fd, 500, "not enough memory");
return;
}
frame = tmp;
}
timestamp = ros::Time::now().toSec();
memcpy(frame, &encoded_buffer[0], frame_size);
ROS_DEBUG("got frame (size: %d kB)", frame_size / 1024);
}
sprintf(buffer, "Content-Type: image/jpeg\r\n"
"Content-Length: %d\r\n"
"X-Timestamp: %.06lf\r\n"
"\r\n",
frame_size, (double)timestamp);
ROS_DEBUG("sending intemdiate header");
if (write(fd, buffer, strlen(buffer)) < 0)
break;
ROS_DEBUG("sending frame");
if (write(fd, frame, frame_size) < 0)
break;
ROS_DEBUG("sending boundary");
sprintf(buffer, "\r\n--boundarydonotcross \r\n");
if (write(fd, buffer, strlen(buffer)) < 0)
break;
}
free(frame);
decreaseSubscriberCount(topic);
unregisterSubscriberIfPossible(topic);
}
void MJPEGServer::sendSnapshot(int fd, const char *parameter)
{
unsigned char *frame = NULL;
int frame_size = 0;
char buffer[BUFFER_SIZE] = {0};
double timestamp;
std::string params = parameter;
ParameterMap parameter_map;
decodeParameter(params, parameter_map);
ParameterMap::iterator itp = parameter_map.find("topic");
if (itp == parameter_map.end())
return;
std::string topic = itp->second;
increaseSubscriberCount(topic);
ImageBuffer* image_buffer = getImageBuffer(topic);
boost::unique_lock<boost::mutex> lock(image_buffer->mutex_);
image_buffer->condition_.wait(lock);
cv_bridge::CvImagePtr cv_msg;
try
{
if (cv_msg = cv_bridge::toCvCopy(image_buffer->msg, "bgr8"))
{
;
}
else
{
ROS_ERROR("Unable to convert %s image to bgr8", image_buffer->msg.encoding.c_str());
return;
}
}
catch (...)
{
ROS_ERROR("Unable to convert %s image to ipl format", image_buffer->msg.encoding.c_str());
return;
}
cv::Mat img = cv_msg->image;
std::vector<uchar> encoded_buffer;
std::vector<int> encode_params;
if (parameter_map.find("invert") != parameter_map.end())
{
cv::Mat cloned_image = img.clone();
invertImage(cloned_image, img);
}
int quality = 95;
if (parameter_map.find("quality") != parameter_map.end())
{
quality = stringToInt(parameter_map["quality"]);
}
encode_params.push_back(CV_IMWRITE_JPEG_QUALITY);
encode_params.push_back(quality);
if (parameter_map.find("width") != parameter_map.end() && parameter_map.find("height") != parameter_map.end())
{
int width = stringToInt(parameter_map["width"]);
int height = stringToInt(parameter_map["height"]);
if (width > 0 && height > 0)
{
cv::Mat img_resized;
cv::Size new_size(width, height);
cv::resize(img, img_resized, new_size);
cv::imencode(".jpeg", img_resized, encoded_buffer, encode_params);
}
else
{
cv::imencode(".jpeg", img, encoded_buffer, encode_params);
}
}
else
{
cv::imencode(".jpeg", img, encoded_buffer, encode_params);
}
frame_size = encoded_buffer.size();
if ((frame = (unsigned char*)malloc(frame_size)) == NULL)
{
free(frame);
sendError(fd, 500, "not enough memory");
return;
}
timestamp = ros::Time::now().toSec();
memcpy(frame, &encoded_buffer[0], frame_size);
ROS_DEBUG("got frame (size: %d kB)", frame_size / 1024);
sprintf(buffer, "HTTP/1.0 200 OK\r\n"
"%s"
"Content-type: image/jpeg\r\n"
"X-Timestamp: %.06lf\r\n"
"\r\n",
header.c_str(), (double)timestamp);
if (write(fd, buffer, strlen(buffer)) < 0 || write(fd, frame, frame_size) < 0)
{
free(frame);
return;
}
free(frame);
decreaseSubscriberCount(topic);
unregisterSubscriberIfPossible(topic);
}
void MJPEGServer::client(int fd)
{
int cnt;
char buffer[BUFFER_SIZE] = {0}, *pb = buffer;
iobuffer iobuf;
request req;
initIOBuffer(&iobuf);
initRequest(&req);
memset(buffer, 0, sizeof(buffer));
if ((cnt = readLineWithTimeout(fd, &iobuf, buffer, sizeof(buffer) - 1, 5)) == -1)
{
close(fd);
return;
}
if (strstr(buffer, "GET /?") != NULL)
{
req.type = A_STREAM;
if ((pb = strstr(buffer, "GET /")) == NULL)
{
ROS_DEBUG("HTTP request seems to be malformed");
sendError(fd, 400, "Malformed HTTP request");
close(fd);
return;
}
pb += strlen("GET /");
int len = min(max((int)strspn(pb, "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ._/-1234567890?="), 0), 100);
req.parameter = (char*)malloc(len + 1);
if (req.parameter == NULL)
{
exit(EXIT_FAILURE);
}
memset(req.parameter, 0, len + 1);
strncpy(req.parameter, pb, len);
ROS_DEBUG("requested image topic[%d]: \"%s\"", len, req.parameter);
}
else if (strstr(buffer, "GET /stream?") != NULL)
{
req.type = A_STREAM;
if ((pb = strstr(buffer, "GET /stream")) == NULL)
{
ROS_DEBUG("HTTP request seems to be malformed");
sendError(fd, 400, "Malformed HTTP request");
close(fd);
return;
}
pb += strlen("GET /stream");
int len = min(max((int)strspn(pb, "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ._/-1234567890?="), 0), 100);
req.parameter = (char*)malloc(len + 1);
if (req.parameter == NULL)
{
exit(EXIT_FAILURE);
}
memset(req.parameter, 0, len + 1);
strncpy(req.parameter, pb, len);
ROS_DEBUG("requested image topic[%d]: \"%s\"", len, req.parameter);
}
else if (strstr(buffer, "GET /snapshot?") != NULL)
{
req.type = A_SNAPSHOT;
if ((pb = strstr(buffer, "GET /snapshot")) == NULL)
{
ROS_DEBUG("HTTP request seems to be malformed");
sendError(fd, 400, "Malformed HTTP request");
close(fd);
return;
}
pb += strlen("GET /snapshot");
int len = min(max((int)strspn(pb, "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ._/-1234567890?="), 0), 100);
req.parameter = (char*)malloc(len + 1);
if (req.parameter == NULL)
{
exit(EXIT_FAILURE);
}
memset(req.parameter, 0, len + 1);
strncpy(req.parameter, pb, len);
ROS_DEBUG("requested image topic[%d]: \"%s\"", len, req.parameter);
}
do
{
memset(buffer, 0, sizeof(buffer));
if ((cnt = readLineWithTimeout(fd, &iobuf, buffer, sizeof(buffer) - 1, 5)) == -1)
{
freeRequest(&req);
close(fd);
return;
}
if (strstr(buffer, "User-Agent: ") != NULL)
{
req.client = strdup(buffer + strlen("User-Agent: "));
}
else if (strstr(buffer, "Authorization: Basic ") != NULL)
{
req.credentials = strdup(buffer + strlen("Authorization: Basic "));
decodeBase64(req.credentials);
ROS_DEBUG("username:password: %s", req.credentials);
}
} while (cnt > 2 && !(buffer[0] == '\r' && buffer[1] == '\n'));
switch (req.type)
{
case A_STREAM:
{
ROS_DEBUG("Request for streaming");
sendStream(fd, req.parameter);
break;
}
case A_SNAPSHOT:
{
ROS_DEBUG("Request for snapshot");
sendSnapshot(fd, req.parameter);
break;
}
default:
ROS_DEBUG("unknown request");
}
close(fd);
freeRequest(&req);
ROS_INFO("Disconnecting HTTP client");
return;
}
void MJPEGServer::execute()
{
ROS_INFO("Starting mjpeg server");
struct addrinfo *aip, *aip2;
struct addrinfo hints;
struct sockaddr_storage client_addr;
socklen_t addr_len = sizeof(struct sockaddr_storage);
fd_set selectfds;
int max_fds = 0;
char name[NI_MAXHOST];
bzero(&hints, sizeof(hints));
hints.ai_family = PF_UNSPEC;
hints.ai_flags = AI_PASSIVE;
hints.ai_socktype = SOCK_STREAM;
int err;
snprintf(name, sizeof(name), "%d", port_);
if ((err = getaddrinfo(NULL, name, &hints, &aip)) != 0)
{
perror(gai_strerror(err));
exit(EXIT_FAILURE);
}
for (int i = 0; i < MAX_NUM_SOCKETS; i++)
sd[i] = -1;
int i = 0;
int on;
for (aip2 = aip; aip2 != NULL; aip2 = aip2->ai_next)
{
if ((sd[i] = socket(aip2->ai_family, aip2->ai_socktype, 0)) < 0)
{
continue;
}
on = 1;
if (setsockopt(sd[i], SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on)) < 0)
{
perror("setsockopt(SO_REUSEADDR) failed");
}
on = 1;
if (aip2->ai_family == AF_INET6 && setsockopt(sd[i], IPPROTO_IPV6, IPV6_V6ONLY, (const void *)&on, sizeof(on)) < 0)
{
perror("setsockopt(IPV6_V6ONLY) failed");
}
if (bind(sd[i], aip2->ai_addr, aip2->ai_addrlen) < 0)
{
perror("bind");
sd[i] = -1;
continue;
}
if (listen(sd[i], 10) < 0)
{
perror("listen");
sd[i] = -1;
}
else
{
i++;
if (i >= MAX_NUM_SOCKETS)
{
ROS_ERROR("Maximum number of server sockets exceeded");
i--;
break;
}
}
}
sd_len = i;
if (sd_len < 1)
{
ROS_ERROR("Bind(%d) failed", port_);
closelog();
exit(EXIT_FAILURE);
}
else
{
ROS_INFO("Bind(%d) succeeded", port_);
}
ROS_INFO("waiting for clients to connect");
while (!stop_requested_)
{
do
{
FD_ZERO(&selectfds);
for (i = 0; i < MAX_NUM_SOCKETS; i++)
{
if (sd[i] != -1)
{
FD_SET(sd[i], &selectfds);
if (sd[i] > max_fds)
max_fds = sd[i];
}
}
err = select(max_fds + 1, &selectfds, NULL, NULL, NULL);
if (err < 0 && errno != EINTR)
{
perror("select");
exit(EXIT_FAILURE);
}
} while (err <= 0);
ROS_INFO("Client connected");
for (i = 0; i < max_fds + 1; i++)
{
if (sd[i] != -1 && FD_ISSET(sd[i], &selectfds))
{
int fd = accept(sd[i], (struct sockaddr *)&client_addr, &addr_len);
ROS_DEBUG("create thread to handle client that just established a connection");
if (getnameinfo((struct sockaddr *)&client_addr, addr_len, name, sizeof(name), NULL, 0, NI_NUMERICHOST) == 0)
{
syslog(LOG_INFO, "serving client: %s\n", name);
}
boost::thread t(boost::bind(&MJPEGServer::client, this, fd));
t.detach();
}
}
}
ROS_INFO("leaving server thread, calling cleanup function now");
cleanUp();
}
void MJPEGServer::cleanUp()
{
ROS_INFO("cleaning up ressources allocated by server thread");
for (int i = 0; i < MAX_NUM_SOCKETS; i++)
close(sd[i]);
}
void MJPEGServer::spin()
{
boost::thread t(boost::bind(&MJPEGServer::execute, this));
t.detach();
ros::spin();
ROS_INFO("stop requested");
stop();
}
void MJPEGServer::stop()
{
stop_requested_ = true;
}
void MJPEGServer::decreaseSubscriberCount(const std::string topic)
{
boost::unique_lock<boost::mutex> lock(image_maps_mutex_);
ImageSubscriberCountMap::iterator it = image_subscribers_count_.find(topic);
if (it != image_subscribers_count_.end())
{
if (image_subscribers_count_[topic] == 1) {
image_subscribers_count_.erase(it);
ROS_INFO("no subscribers for %s", topic.c_str());
}
else if (image_subscribers_count_[topic] > 0) {
image_subscribers_count_[topic] = image_subscribers_count_[topic] - 1;
ROS_INFO("%lu subscribers for %s", image_subscribers_count_[topic], topic.c_str());
}
}
else
{
ROS_INFO("no subscribers counter for %s", topic.c_str());
}
}
void MJPEGServer::increaseSubscriberCount(const std::string topic)
{
boost::unique_lock<boost::mutex> lock(image_maps_mutex_);
ImageSubscriberCountMap::iterator it = image_subscribers_count_.find(topic);
if (it == image_subscribers_count_.end())
{
image_subscribers_count_.insert(ImageSubscriberCountMap::value_type(topic, 1));
}
else {
image_subscribers_count_[topic] = image_subscribers_count_[topic] + 1;
}
ROS_INFO("%lu subscribers for %s", image_subscribers_count_[topic], topic.c_str());
}
void MJPEGServer::unregisterSubscriberIfPossible(const std::string topic)
{
boost::unique_lock<boost::mutex> lock(image_maps_mutex_);
ImageSubscriberCountMap::iterator it = image_subscribers_count_.find(topic);
if (it == image_subscribers_count_.end() ||
image_subscribers_count_[topic] == 0)
{
ImageSubscriberMap::iterator sub_it = image_subscribers_.find(topic);
if (sub_it != image_subscribers_.end())
{
ROS_INFO("Unsubscribing from %s", topic.c_str());
image_subscribers_.erase(sub_it);
}
}
}
}
int main(int argc, char** argv)
{
ros::init(argc, argv, "mjpeg_server");
ROS_WARN("WARNING -- mjpeg_server IS NOW DEPRECATED.");
ROS_WARN("PLEASE SEE https://github.com/RobotWebTools/web_video_server.");
ros::NodeHandle nh;
mjpeg_server::MJPEGServer server(nh);
server.spin();
return (0);
}
2.遠隔のホストPCのブラウザにカメラ画像を表示
以前の記事を参考にして
・VNC接続したJetson Nanoを用意
・USBカメラ(ロジクール)をJetson Nanoに接続
・Jetsonでコマンド実行- UCBカメラ起動-ブラウザに送信
・ホストPCのブラウザで映像確認 Jetson Nano side
$ ls /dev/video*
>>
$ ifconfig
$ roscore
$ roslaunch roscam_capture usb_cam.launch
$ rosrun video_stream video_stream _port:=10000
Jetson Nanoとの共有画面
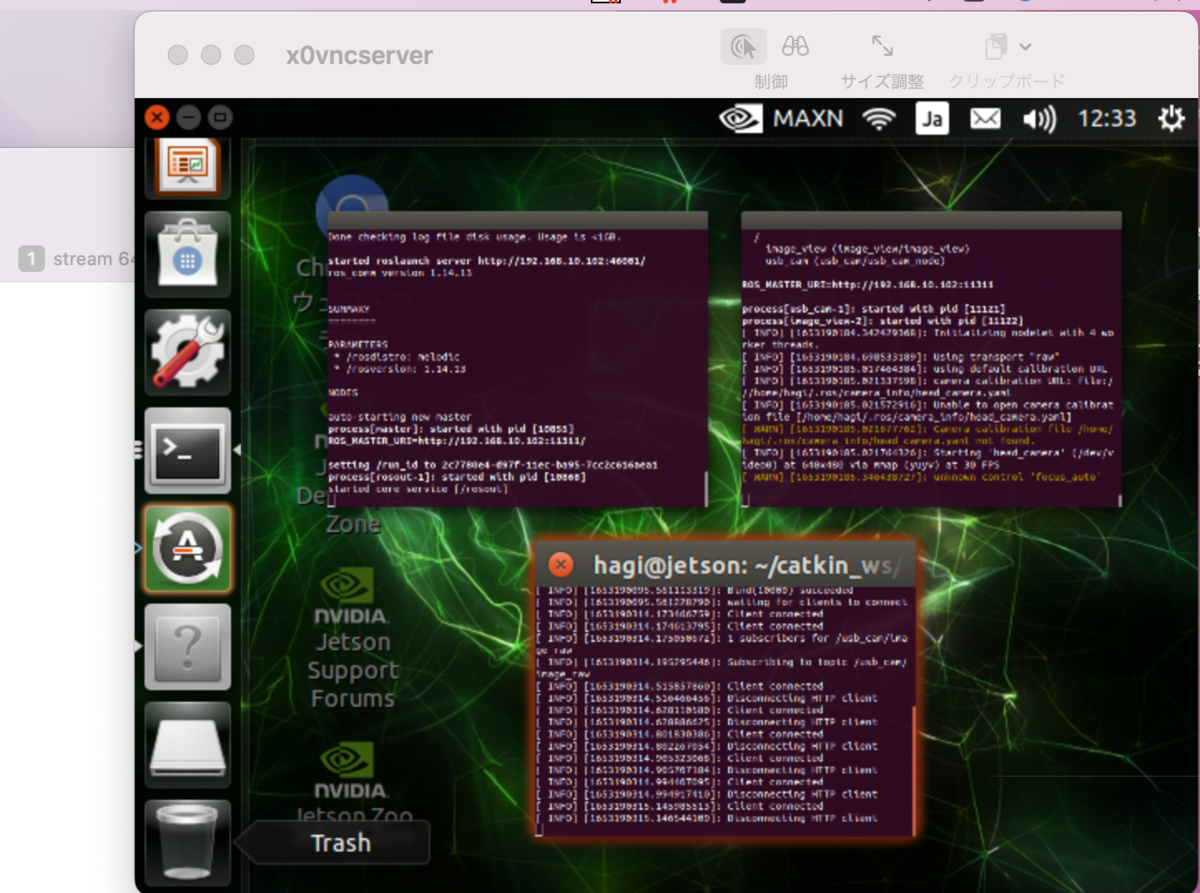
ホストPC side
Safariでアクセス
トピック名=/usb_cam/image_raw
アドレス = http://1xx.xxx.10.xxx:10000/stream?topic=/usb_cam/image_raw

PCでは無事みれたけど、スマホとかipadでは見れなかった。
Web socketでjavascriptを使う方法もあるけど、こっちのがROSと併用できて、使いやすい。
VPNがもう使えるので、遠隔監視ロボかシステムでも作れそう。
参考
・
mjpeg_server
・
【WebSocket】Raspberry Piロボットに搭載されたカメラの映像を遠隔PCに配信する