Blazefaceはgoogleの訓練済みのデバイス用の顏/手の認識モデルで速くて高性能なモデル。
役割は顔/手の位置とキーポイントを高速に検出する機械学習モデル。
BlazeFaceはMobileNetをバックボーンをベースにして作られてる。
今回はやることは
2.それで、本来のMobileNetバックボーンに加えて、Resnetバックボーンのblazefaceを自作する。
3.自作ResNetバックボーンにMobileNetバックボーン(本家)の性能を「蒸留(Distillation)」を使って移植し、再現。
なので今回はその備忘録。
目次
1.Distillationについて
2.今回使ったloss
3.Resnetベースのバックボーンモデル
4.蒸留の精度
5.精度曲線とloss曲線
1.Distillationについて
蒸留はかなりやり方が多様で、クリエイティビティな側面が大きい。
個人的に下の神記事のWavenetとやり方とkaggleのサイトがかなり参考になった。
・Distillation Implementation with Freesound2
・Deep Learningにおける知識の蒸留
BlazeFaceは出力が2つある。
・出力1はクラスの確率
なので、出力1を蒸留用のlossに使うことにした。
あとは普通に出力1, 2の教師あり学習データは、pseudo-labelingで代用。
蒸留の仕組み
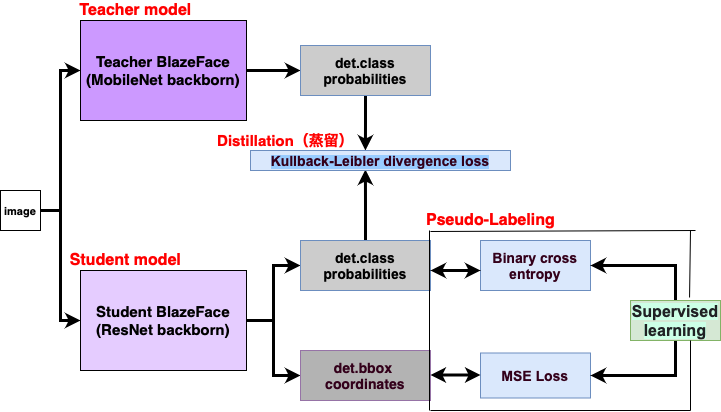
BlazeFaceの出力部分
class BlazeFace(nn.Module): 〜〜〜〜〜 c = torch.cat((c1, c2), dim=1) # (b, 896, 1) r1 = self.regressor_8(x) # (b, 32, 16, 16) r1 = r1.permute(0, 2, 3, 1) # (b, 16, 16, 32) r1 = r1.reshape(b, -1, 16) # (b, 512, 16) r2 = self.regressor_16(h) # (b, 96, 8, 8) r2 = r2.permute(0, 2, 3, 1) # (b, 8, 8, 96) r2 = r2.reshape(b, -1, 16) # (b, 384, 16) r = torch.cat((r1, r2), dim=1) # (b, 896, 16) return [r, c] 〜〜〜〜〜
以下の部分が蒸留で大事なのではと思った。
・Softmax with Temperature(SwT)はKL Divergence_lossと併用が一般的。
・なるべく蒸留はlossでは確率分布を学びやすいように目的に合わせて、前処理する。
・教師あり学習はラベル問題とかセグメンテーションタスクみたいにリアルなデータを使うのが普通だが、教師データがなくてもpseudo-labelingでもいけた。
・lossはMSE以外にも出力が似るように収束するlossならOK。
2.今回使ったloss
蒸留用lossと教師ありデータ用lossでうまくいったのは下の2つ。蒸留用lossは一般的なnn.KLDivLoss()を使って、確率分布を前処理する形にした。
教師ありも本家のlossとは違い、出力が似やすいように前処理した。
1つ目:best性能loss。前処理重視でMAEnn.L1Loss()とかMSEnn.MSELoss(), F.binary_cross_entropyを使った
import torch import torch.nn as nn import torch.nn.functional as F def kl_divergence_loss(logits, target): T = 0.01 alpha = 0.6 thresh = 100 criterion = nn.L1Loss() # c : preprocess for distillation log2div = logits[1].clamp(-thresh, thresh).sigmoid().squeeze(dim=-1) tar2div = target[1].clamp(-thresh, thresh).sigmoid().squeeze(dim=-1) closs = nn.KLDivLoss(reduction="batchmean")(F.log_softmax((log2div / T), dim = 1), F.softmax((tar2div / T), dim = 1))*(alpha * T * T) + criterion(log2div, tar2div) * (1-alpha) # r anchor = load_anchors("src/anchors.npy") rlogits = decode_boxes(logits[0], anchor) rtarget = decode_boxes(target[0], anchor) rloss = criterion(rlogits, rtarget) return closs + rloss
def kl_divergence_loss(logits, target): T = 0.01 alpha = 0.6 thresh = 100 criterion = nn.MSELoss() # c : preprocess for distillation log2div = logits[1].clamp(-thresh, thresh).sigmoid().squeeze(dim=-1) tar2div = target[1].clamp(-thresh, thresh).sigmoid().squeeze(dim=-1).detach() closs = nn.KLDivLoss(reduction="batchmean")(F.log_softmax((log2div / T), dim = 1), F.softmax((tar2div / T), dim = 1))*(alpha * T * T) + F.binary_cross_entropy(log2div, tar2div) * (1-alpha) # r anchor = load_anchors("src/anchors.npy") rlogits = decode_boxes(logits[0], anchor) rtarget = decode_boxes(target[0], anchor) rloss = criterion(rlogits, rtarget) return closs + rloss
Tを0.01〜10にしてもあんまり影響なく、いかに蒸留と教師あり学習のlossを上手く学びやすい形にするかが重要。
2つ目:あんまり性能出なかったloss。前処理しないと多分、blazefaceみたいな特殊な出力はうまく蒸留できない。
def kl_divergence_loss(logits, target): T = 0.01 alpha = 0.6 thresh = 100 criterion = nn.L1Loss() # c : preprocess for distillation log2div = logits[1].clamp(-thresh, thresh).sigmoid().squeeze(dim=-1) tar2div = target[1].clamp(-thresh, thresh).sigmoid().squeeze(dim=-1) closs = nn.KLDivLoss(reduction="batchmean")(F.log_softmax((log2div / T), dim = 1), F.softmax((tar2div / T), dim = 1))*(alpha * T * T) + criterion(logits[1], target[1]) * (1-alpha) # r rloss = criterion(logits[0], target[0]) return closs + rloss
def kl_divergence_loss(logits, target): T = 0.01 alpha = 0.6 thresh = 100 criterion = nn.MSELoss() # c : preprocess for distillation log2div = logits[1].clamp(-thresh, thresh).sigmoid().squeeze(dim=-1) tar2div = target[1].clamp(-thresh, thresh).sigmoid().squeeze(dim=-1) closs = nn.KLDivLoss(reduction="batchmean")(F.log_softmax((log2div / T), dim = 1), F.softmax((tar2div / T), dim = 1))*(alpha * T * T) + criterion(logits[1].squeeze(dim=-1), target[1].squeeze(dim=-1)) * (1-alpha) # r anchor = load_anchors("src/anchors.npy") rlogits = decode_boxes(logits[0], anchor) rtarget = decode_boxes(target[0], anchor) rloss = criterion(rlogits, rtarget)
3.Resnetベースのバックボーンモデル
Resnetベースはresnet18の構造はMobilenetのモデルにresidual構造を加えたネットワークを自作。
residual構造にした部分
class BlazeFace(nn.Module): 〜〜〜 if self.resnet_backborn: print('resnet base') inputs = x o1 = self.conv(inputs) o2 = self.relu(o1) o3 = self.b1(o2) o4 = self.b2(o3) + self.resconv1(o2) o5 = self.b3(o4) o6 = self.b4(o5) o7 = self.b5(o6) + self.resconv2(o5) o8 = self.b6(o7) o9 = self.b7(o8) o10 = self.b8(o9) o11 = self.b9(o10) o12 = self.b10(o11) + self.resconv3(o8) x = self.backbone1(o12) # (b, 88, 16, 16) x1_ = self.b11(x) x2_ = self.b12(x1_) x3_ = self.b13(x2_) + x1_ x4_ = self.b14(x3_) h = self.backbone2(x4_) + x1_ # (b, 96, 8, 8) 〜〜〜
4.蒸留の精度
実験1.
MobileNetベース(googleのやつ)


Resnetベース(蒸留したやつ)


ほとんど本家のblazefaceと同じ精度。蒸留ってすご。
5.精度曲線とloss曲線
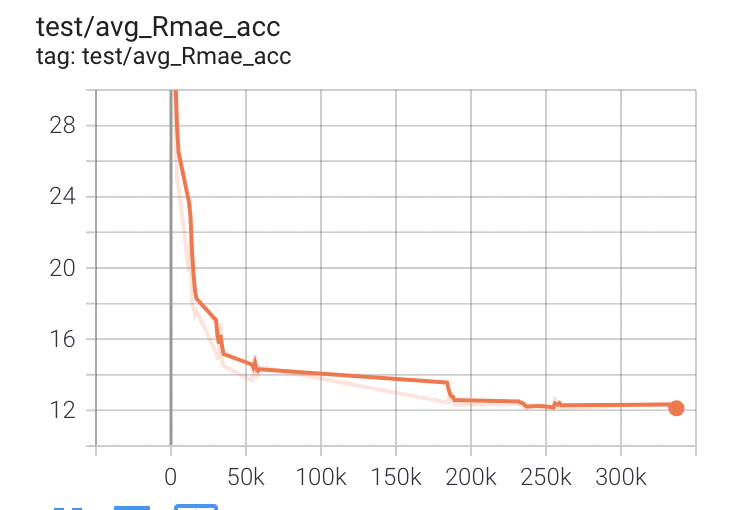
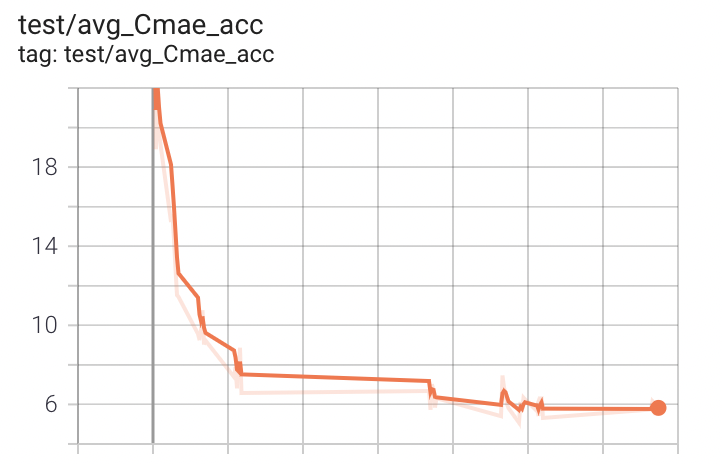
精度曲線(MAE)
R出力(出力1)
C出力(出力2)
loss曲線
train loss
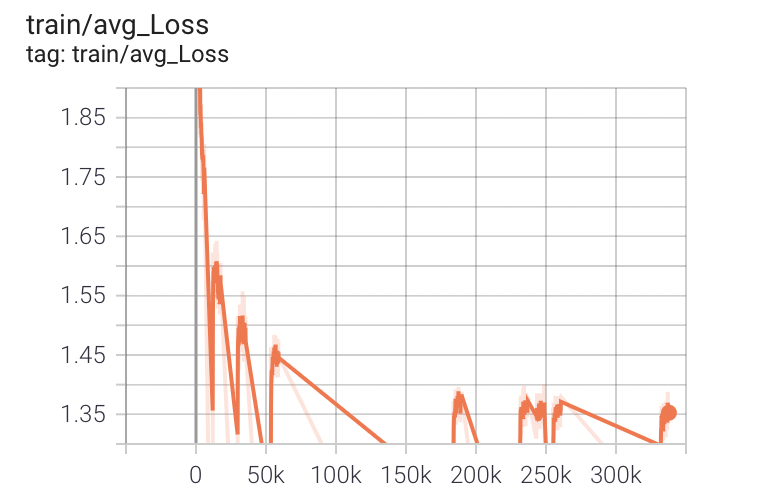
validation loss
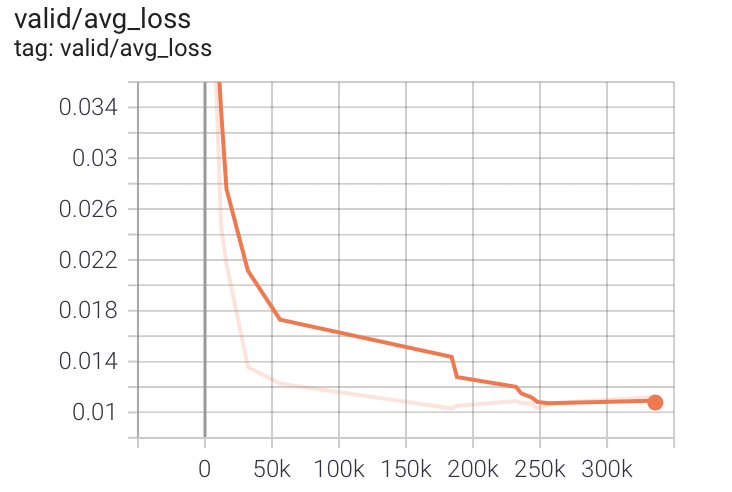
初めは全然違うが段々、値が似てくる。評価用のテストスクリプトでテストできるようにして、なるべく高速で多くPDCAが回しやすいようにした。
tensorboardのグラフでデータがかなり客観的でにとらえられた。
今回初めてだったけど、かなり上手くいった。
教師データがないのが痛かったけどpseudo-labelingで上手いように学習できたのは前処理でさんざん悩んだおかげ。
蒸留は、ハードウェアでは、The・トレンド感な技術なだけあって、今回みたいな変な出力を蒸留するのは相当難かった。
精度はかなり忠実に移植できたので、相当いい結果になったつもり。